Google Author Rank involves the Google search engine’s methodologies to understand, define and rank an author for a topic for the author’s expertise, authority, and validity. Google can understand the author’s vectors, language, and even accent from the audio recordings. Facial recognition, voice recognition, or even action recognition help search engines to differentiate a person from another. Thus, a search engine can use only specific users’ search sessions to understand the click satisfaction models, like using only specific authors to understand the expertise threshold for a topic. Especially, in the News of SEO, the authors increase their SEO Value as Google search engine continues to add more Search Engine Result Pages just for author named entities along with specific features.
Google Author Rank, Google Agent, Google Author Digital Signature, Google Answers, Google Plus, and many more other search engine improvements from the past touch the Google Author Rank definition, prominence, and functionality.
In this article, the questions below will be answered.
- What is Google Author Rank?
- What is Google Agent?
- What are Author Tags?
- How does Google track Authors?
- Do Google Rank Authors based on their expertise?
- How does Google recognize Author-Named Entities?
- What are the patents for Author Recognition?
- How to use Author Rank in SEO?
- How to Use Ahrefs-like tools for Author Finding?
This research for Google Author Rank explains how Google knows authors, understands which content belongs to which author, and how Google ranks authors for certain topics with their authorship. Google’s methods for authority understanding, author reconciliation, and author SERP features, or structured data representations, Google authorship patents, and designs for understanding who is the real author behind the article and main content are explained with scientific and practical proofs.
What is Google Author Rank?
Google Author Rank is a term to describe Google’s understanding of the authorship of the documents. Google Author Rank is planned to be used for ranking the documents based on the reputation of an author. Google Author Rank contains a new ranking argument besides the PageRank or Information Retrieval Score. Author Rank is an important concept to describe the prominence of the Expertise of an Author for Search Engine Optimization, and the Search Engine User Satisfaction. Google Author Rank is announced within the Google Agent Patent and implemented in Google Plus. Google Talk and Google Answers were different projects that focused on the authorship, and recognition of the search engine users with their social behaviors. Google has patented many designs to index the author information, and serve them within the search engine result pages. Google Author Rank concept affects the understanding of authorship perspective of Google search engine while creating different focuses to interpret the quality of a web page document.
Is Google Author Rank and Google Agent the same?
No, Google Author Rank is a generalized concept for describing Google’s author recognition from web page documents and comments, while Google Agent is a concept from the Google Patents. Google Agent Patent has been invented by David Minogue and Paul A. Tucker. The Agent Rank patent was filed on 8 August 2005. Since the Agent Rank patent is relatively old, it shows that it touches a fundamental thought and design of Google.
Google’s fundamental designs and understanding don’t change over time. Thus, Google Agent is perceived as a first design and raw mindset for understanding the authorship on the open web.
The Google Author Rank-related old Google Products are listed below.
- Google Answers
- Google Talk
- Google Plus
- Google Knol
- Google Sidewiki
- Google Groups
What are Google Answers? Why is Relevant to Google Author Rank?
Google Answers is a search engine project that focuses on social activity on the open web. Google is a hybrid search engine that focuses on different verticals on the open web. Google Answers is the first social forum that a search engine has ever created. Google Answers is created to provide a profile for the people who want to give answers to certain questions on certain topics.
Another prominent aspect of Google Answers is that a user was able to tell his or her opinion about any web page document on the open web via Google Answers. Thus, Google was able to gather user perspectives for a specific topic and also web page document quality directly. If a user answers many questions on a certain topic, it means that the person is an expert or a kind of hobbyist in the knowledge domain.
Google Answers had a subdomain within the Google main domain. Today, it still lives. Since there is a chance that Google might remove the entire domain one day, entire Google Answers have been crawled and scraped by Holistic SEO & Digital for further search engine research.
Google Answers is relevant to the Google Author, due to the reasons below.
- Google Answers provide an authorship profile for the question and answer owners.
- Google Answers let users tell their opinion about a web page from a topic by stating the author’s success.
- Google Answers give direct feedback from the authors for an answer quality, which affects the expertise level of the specific author.
- Google Answers was providing a web-wide commenting and discussion platform while giving the search engine a chance to aggregate data for quality answers from certain authors.
A screenshot from the Google Answers, and how the answers are categorized for different main topics, can be seen below.

Below, a specific search activity from Google Answers can be seen.
It brings us to the Google Answers restricted search results from the Google search engine. Below, an answer for the Google Answers can be seen.

The categorization of the questions and the users’ information is as follows.

Google Answers is abolished by Google due to the high level of web spamming, and the usage statistics. But, Google didn’t give up on its social search engine purposes.Thus, Google Answers and Google Talk are connected to each other with Google Author Rank.
What is Google Talk? Why is Relevant to Google Author Rank?
Google Talk was a service for providing instant messaging and text communication between Google search engine users. Gchat, Gtalk or Gmessage were some other names of Google Talk. Google Talk had a mobile app to provide mobile-friendly social networking. Google Talk became Google Hangouts, later. And, at the moment, Google Hangout is being transferred to Google Meet. Google is a hybrid search engine that focuses on ambiance optimization. Google Meet is vastly used for educational and business purposes by different types of users and organizations. Thus, Google Meet is a social search engine feature that provides social networking for businesses and search engine users. Google Talk is relevant to the Google Author because Google Talk has used the Gmail Accounts for the creation of the profile. Google Plus at the same time provided a possibility to create an account with the Gmail accounts. Thus, ambient optimization has played a major role in uniting the users’ messaging, searching, and social networking needs under Google Products. Google Talk was also a prominent product to take the users from other messaging platforms such as EarthLink, Gizmo5, Tiscali, NetEase, or Orkut. Google Talk provided a vast amount of data for the dialogues, and the conversations between humans to understand the human language with Natural Language Processing further. It also provided a vast amount of advertisement possibilities.
Google Author Rank and Google Talk are relevant to each other in terms of uniting the user profiles under a search engine platform and helping users to comment, communicate, and talk further around a certain topic. Google Talk helped Google users network around the world for certain information transfers.
What is Google Plus? Why is Google Plus Relevant to the Author Rank?
Google Plus was a service for helping search engine users to define themselves with their hobbies, thoughts, personalities, and interests within a social network. Google Plus is a product that shows Google cares about Social Networking. Google Plus is sometimes called Google+, or G+. Google Plus was launched on 2011, June 28 to compete against other social media platforms. In the context of ambiance optimization, Google connected the Google Plus profiles to Gmail, Google Drive, Blogger, YouTube, and some others. Google Plus was abolished by Google later due to security and privacy issues. Other developers were able to reach out to the information from Google Plus related to the users’ private data. Google+ is transferred into Google Currents, and later it became Google Chat with its users.
Google Plus is relevant to the Google Author Rank because Google Plus provided an authorship profile for all users. Google Plus is used within the Author Markup, and the “author” attribute within the HTML documents for Google. Google tried to perform its Agent Rank design with Google Plus. Due to the low level of engagement, and web spamming, Google Plus has been removed from the Google environment.
After Google Plus, Google started to collect the author’s information with entity-oriented search. Instead of registering every author, or the blogger into a networking platform, they organized the web pages and the documents around the named entities as persons with authorship. Today, Google is able to show author knowledge panels, and books, articles, or publications for different authors from different sources. Google ranks news results based on many relevances and authority signals, including authorship. In some patent designs, Google defines the authors as a website section or website section definition.
Google Authorship is understood as electronic system registration, but it is developed as an open web information extraction system for authors’ identity and artwork collection.
What is Google Knol? Why is Google Knol Relevant to the Google Author Rank?
Google Knol is an old encyclopedia product to compete with Wikipedia. Google Knol is relevant to Google Author Rank because users were using their own real names and Googlemail (gmail) during registration and writing their articles. Google Knol provided an opportunity for the users to show their expertise on a topic. The main difference between Wikipedia and Google Knol was that on Wikipedia, every user writes the same article, together with authoritative editors, while on Google Knol users write different articles for the same topic. A side difference of Google Knol from Wikipedia was that it let users use Adsense on their own articles. The ads revenue, links, copied content, and lack of editorship cause bloat on the Google Knol. Since the overall content quality was lower, it caused users to not be able to find the valuable and real authoritative information that they need.

On some other media channels, Google Knol was criticized as a counter-attack for the digital democracy or the news media enemy. The reason for these criticisms was that Google Knol was seen as a repetitive content production point while causing bloat of the web. Collecting all the users in the Google Knol didn’t provide better answers, and there was speculation that Google would rank Google Knol articles better as the result of a “conflict of interest”. Due to the clear failure of Google Knol, Google abolished it in 2013. Google Knol lived for 6 years from 2007 to 2013.
Google Knol and Google Author Rank are relevant to each other. Google Knol helps users to see who are the experts on a topic, how they are actually writing, and how the commentators react to their content. Google Knol used Google Plus, and Gmail for registration while creating consistency for the Google Agent Rank design in the context of the unification of all the author profiles on the same point.
It is also interesting to see that Wikipedia articles are much better than Google Knol articles thanks to strict writing guidelines. It was also better for user satisfaction. One good article is better than 1000 different incomplete and non-authoritative articles.
Thus, it shows us that a single institution can be more authoritative than, 10000 different authors. And, a single article can be a better authoritativeness signal than 10000 articles, or authors. This perspective shaped Google’s Panda and Penguin fundamental updates, and today’s “SERP Diversification” with “probable probabilities”.
What is Google Sidewiki? Why is Google Sidewiki Relevant to the Google Author Rank?
Google Sidewiki was a web annotation technology from Google. Google Sidewiki was launched in 2009 as a web-wide annotation and commenting system to support the collaboration of web users. Google Sidewiki was a browser extension that users used with their Google Mail (gmail) accounts. Google Sidewiki works as a sidebar that is loaded from the browser for every website. It aimed to show the other users’ thoughts on the existing web pages. In 2009, Google used the “PageRank” values on the Google Search Engine Result Pages to show the authoritativeness and the possibility of satisfaction from visiting the web page. Similarly, Google Sidewiki aimed to show the authoritativeness and the possibility of satisfaction of a web page from the comments and experiences of other users. It also helped Google engineers to collect data directly from the users to understand the authoritativeness of the websites for a topic.
It is interesting to see that every Google Authorship-related product eventually leads the search engine understanding process to the Authority and Expertise along with Topicality, or in short, Topical Authority. In this context, Google Sidewiki is relevant to the Author Rank. Google Sidewiki is connected to Google Plus and Google’s attempts to understand the interest areas of users, and how they are shaped or connected. Google Sidewiki provided an extensive amount of information from the users, their satisfaction, and their expertise along with how to weigh the user feedback for a web page.
Google Sidewiki was shut down in September 2011 due to heavy criticism and spamming. Google’s Ceaser Sengupta claimed that if the users’ comments are connected to their legal names and Google Profiles, they wouldn’t lie, or put trivia in their comments to protect their digital identity. But, in reality, the Google Sidewiki was a nest of web spammers to manipulate the users, or Google’s perception. Google Sidewiki is also criticized because it was taking the comments of the users from the websites and putting them into Google’s product. It is seen as “robbing the websites” within “channel conflict”.
Google Sidewiki is also prominent to demonstrate the prominence of “Comment Relevancy”. Comment relevancy represents the relevance of a comment text to the commented item. Later, Google’s search engine started to use “ItemReview” structured data to understand the reviews and comments. Google started to use the “User-generated Content” link attribute for counting the User Generated Content’s relevance and the links in the comment. Google also started to use Website Operators’ reviews of products on its SERP, while publishing the Product Review Update.
All these improvements should be seen as relevant to the days of Google Sidewiki, and the heavy critics that are taken. If you read Steven Levy’s In The Plex, you understand how Google plans and acts.
What is Google Groups? Why is Google Groups Relevant to the Google Author Rank?
Google Groups is a collaborative discussion group service that Google provides. Google provides a shared user interface for the users, it also provides a mailing list for the Google Group Members. Google Groups collect people on the open web around certain topics. It helps users to ask questions, answer and add materials. Google Groups can be used with Gmail Accounts. Google Groups is one of the oldest Google Products. It was launched in February 2001.
Google Groups started as a service from Deja News, but in 2001 Google bought Deja News and integrated it into the Google Search Engine. Google Groups were a competitor to the Windows Live Groups, Yahoo! Groups, MSN Groups, or GroupSpaces from different search engine brands. Google Groups are heavily used for spamming since it provides a chance for linking other domains from Google Products. Google Groups are criticized due to the certain content on it, and even Turkey banned it for a month due to the content that is shared in some groups.
Google Groups are relevant to the Google Author Rank because it provides a question and answer platform in a collaborative way. Google Author Rank focuses on the expertise of people on the web-based on the topics. Google Groups help a search engine to collect data for the interest areas, topical borders, and user behavior, along with the understanding of “criticism”, “jokes”, “sarcastic”, “methodologic answers”, “factual answers” and furthermore. Thus, an authoritative account from Google Groups can be connected to the other profiles of the same users from the open web for a specific topic or the industry. A consistent author profile and expertise is a useful and trustworthy signal for a search engine to see the authority of a person on a topic.
What are the Google Patent Designs for the Google Authorship Algorithms?
Google Authorship Algorithms involve the algorithms that recognize and define an author while collecting the information for the artwork of the author. Google Authorship algorithms work on different verticals of the search engine result pages and features, from knowledge panels to Google Books, Scholar, or News.
Main Google Authorship Algorithm Designs and Patents are listed below.
- System and Method for Confirming Authorship Documents
- The reputation of an author of online content
- Agent Rank
- Content Author Badges
- Ranking authors and their content in the same framework
- Author Vectors
- Generation of Website Representations Vectors
1. The System and Method for Confirming Authorship Documents
The System and Method for Confirming Authorship Document is a Google Patent design that was invented by Othar Hansson, Sagar Kamdas, and Michael Cassidy. It focuses on the Authorship of documents by the entity, and confirmation from the profiles that are associated with them.

To authenticate the authorship of the document, the patent focuses on entity-related profile links. John Mueller of Google approved that for Entity Reconciliation they focus on the links of the authors to understand who is really who. At the same time, Matt Cutts said many times that they focus on the authorship of the authors to understand how we can rank the real experts better. Since E-A-T is mentioned more than 150 times in Google’s Quality Rater Guidelines, Entity-reconciliation should be seen as a major point. The design’s modular structure can be seen below.

Authorship Identifiers, Confirmation Status, and Content Associated with Entities are prominent concepts to show how to define an author and the associated content. The identifiers of the authorship and confirmation status are connected to each other. But still, it might not be good enough to relate the Content to the Author, if the topic is different. In fact, Author Vectors of Google is also designed for this purpose. One more diagram from the specific design is below.

It shows that the Links, Content, and other types of identifiers work together whether it is on profiles or the documents’ content.
4 key arguments from the specific patent design are below.
- The Authorship identifier might include an email address or social media link. But, the email address is more authentic since the search engine can verify the email address directly if it uses Google search engine products.
- If the Entity is mentioned on certain social media profiles, and the links from multiple documents redirect the users to the same person, it is a clear signal for the search engine.
- Patent design defines a “non-confirmed authorship” which is a signal for missing information about the author.
- Patent design is created based on certain Google services and their logic, thus from time to time, it mentions email verification as in agent rank.
6 key quotes from the patent design are below.
- “The authorship identifier includes an email link to an email address for a purported author of or contributor to the first document, and wherein the email link includes a predefined authorship attribute.”
- “Wherein prior to conditionally confirming the authorship of the first document, the method includes requesting that the entity confirm that the email address associated with the profile for the entity is the email address that the entity includes in documents authored by the entity.”
- “Wherein the authorship of the first document is confirmed, and the confirmed authorship process comprises adding the first document to a social networking webpage for the entity.”
- “Wherein the authorship of the first document is confirmed, and the confirmed authorship process comprises adding information relating to the first document to a webpage including information relating to documents that the entity authored.”
- “Wherein the authorship of the first document is confirmed, and the confirmed authorship process comprises associating the first document with the entity in a search index.”
- “Instructions to determine that the first document has a non-confirmed authorship when no profile for the entity associated with the authorship identifier can be found or when the profile for the entity does not indicate that the entity has confirmed that the authorship identifier is included in documents authored by the entity.”
The reputation of an Author of Online Content is a Google Patent that is designed and invented by William Brougher, Nathan Stoll, Stephan D. Kamvar, and Michael D. Dixon. The patent design focuses on Google’s search engine’s optimization process to understand the authorship, and authors’ reputation.
The System and Method for Confirming Authorship of Documents focus on ID verification of authors while the reputation of an author of online content focuses on the author’s reputation, and authenticity for a topic.
The key designs and diagrams from the Reputation of an Author of Online Content in the context of Google Author Rank are below.

There are two prominent concepts here, “content item”, and “Reputation Score”. The Reputation Score has been mentioned by the multiple different Google Patent designs before, from “Author Reputation”, to the “Influencer Reputation”, usually “Reputation” and “Quality” are connected to each other. Thus, an author’s reputation score can signal the quality of the content, along with user satisfaction.
In the context of Google Knol, we see the concept of “Knol” here related to the authors and their content items. Knol means “unit of knowledge” in Google’s terminology.

The diagram above shows that there will be a single CMS for multiple different authors, which again reflects the Google Knol system. Understanding Google Products and Google Designs in a correlated way help to understand search engines further for SEO contexts.

The diagram above demonstrates how Google can evaluate the author’s quality and reputation. For example, the suggestions, reviews, ratings, comments, discussion, revisions and active history, account existence, read and write percentages, and more. This is a little similar to the YouTube Recommendation system.

As we mentioned before, Google Knol had publishers and authors, and also a content management system with monetization. It is also interesting to see that Google connects publisher and author around money, and they are connected to the community, which signal how they understand the society in a digital environment.

Authentication Score is another concept for helping authors to compete with each other, and it comes from the activities of the users.

Google planned to help users to show their online revenue from the Google Knol for incentivizing other authors to the platform.

Content update audits and audit checks are prominent to understand that a search engine cares when a content changes, and for what. It can also affect the author’s reputation.
3. Agent Rank
Agent Rank is an invention that provides methods and apparatus for understanding the identity, and prominence of an author and web search engine users with digital signatures. The digital signature can be any kind of signature that approves that the author is the same person as the content publisher. Google Inventors for the Agent Rank are Paul A. Tucker and David Minogue.
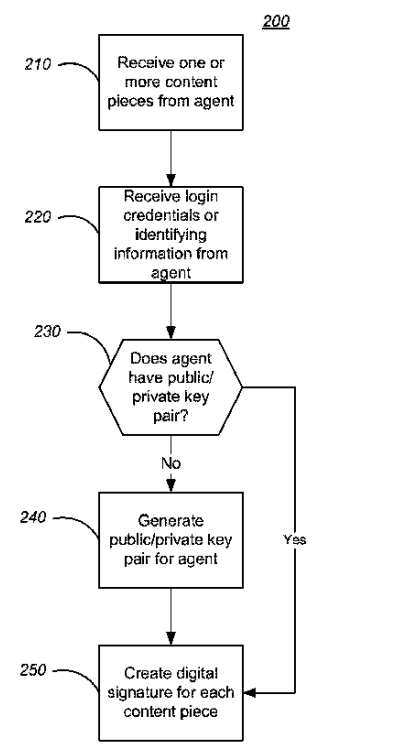
Even if the Agent Rank focuses on specific authorship identification with specific technology designs, still it is relevant to the latest Author Vectors to understand authorship. Google Plus and the Agent Rank are relevant to each other in terms of Google Author Rank. The digital private and public key pair for agents represents Google Plus since it provides a login credential for the social community content publishers.
Google also expresses a web page example with characteristics.

The characteristics of the web page example above and the quote from the Agent Rank below are connected.
“Information Retrieval (IR) is concerned with locating desired elements of information among a large corpus. A search engine is one example of an IR system that enables documents (usually but not necessarily limited to text) to be retrieved from a large corpus on the basis of their degree of relevance with respect to a compact query presented by a user. The order in which documents are retrieved or presented is the ranking created by the search engine: the highest-ranked documents, with respect to the query, are returned or presented first.”
Google Agent Rank Patent and Design for Google Authorship
And the main role and the purpose of the Agent Rank design are below.
“For some information sources, all the content is under the control of a single agent. In such cases, the reputation of the agent can be directly correlated with the content of the information source. In other cases, however, control may be delegated among several agents, each controlling a partition of the information source. To the extent that these partitions can be identified, agent reputation can be calculated at the partition level.”
Google Agent Rank Patent and Design for Google Authorship
In the previous Google Authorship Rank-related designs and patents, we have seen that some authors are not the writer but also contributors. The same example and possibility are mentioned in the Agent Rank design as below.
“Each of these content pieces can be created by a different agent. For example, in one implementation, the main body text 105 is created by the owner of the web page 100, the comment 110 is authored by a first agent of the web page 100, and the comment 115 is authored by a second agent of the web page 100. An agent is an individual or entity that either provides content pieces, edits existing content pieces, or reviews existing content pieces on a web page. An owner of a web page is the agent that has ultimate control over the web page, including control over all the content pieces of the web page, including content pieces provided by other agents. Agents that are not owners generally have limited control over content pieces on the web page. For example, in one implementation, a non-owner agent can place a comment on the web page, but not edit or delete the comments of other agents that are included within the web page.“
Google Agent Rank Patent and Design for Google Authorship
In other words, the sections on a web page can be from different authors. An author’s reputation and authority can be affected by the other authors that appear together. A web page can have a review, and review author, the main article can be from someone else, and the image of the article can be again from someone else.
All these combinations help a search engine to understand the difference between the main author of the web page, and the contributors to the main content of the web page with reviews, comments, or other materials. Algorithms like VIPs and neural network-based web page layout understanding systems matter because of this even further, because without seeing the page segments, the author and content pairs can’t be created.

Creating a digital signature for each content piece contains connecting a content item to an agent in the context of ranking. Giving credit to the real experts on a topic is prominent to see how the influencers, opinion leaders, or exceptional talents behave on the open web. In this context, the Agent Rank takes help from PageRank as below.

Another prominent note here is that search engines rank agents, documents, anchor tags, or news based on the “total number of X”. In other words, if there are more candidates than before, all scores will be normalized further. The Agent count in the agent database will increase the need for the reference link to the documents of the agent, comments, and other types of positive feedback. This is called “Relative Ranking”, and is defined as below.
The agent ranks can optionally also be calculated relative to search terms or categories of search terms. For example, search terms (or structured collections of search terms, i.e., queries) can be classified into topics, e.g., sports or medical specialties, and an agent can have a different rank with respect to each topic… Assuming that a given agent has a high reputational score, representing an established reputation for authoring valuable content, then additional content authored and signed by that agent will be promoted relative to unsigned content or content from less reputable agents in search results.
Google Agent Rank Patent and Design for Google Authorship
The section above also demonstrates what Topical Authority is. As in the “Seed Source” and “Seed Website” definition, the search engine also uses the term “seed agents” as below.
In an alternative implementation, a seed group of trusted agents can be pre-selected, and the agents within this seed group can endorse other content. Agents whose content receives consistently strong endorsements can gain a reputation. In either implementation, the agent’s reputation ultimately depends on the quality of the content that they sign.
Google Agent Rank Patent and Design for Google Authorship
4. Content Author Badges
Content Author Badges is a Google Patent that was invented by Reza Behforooz, Bradley J. Fitzpatrick, and David Glazer. Content Author Badges focus on improving the authorship with certain types of design elements in the digital environment. The David Glazer is important for understanding social media behaviors, and how they are perceived on the Google Side. He performed a presentation to explain the place of social media for Google search systems.
Below, you can find his words for social media and Google relations.
People are naturally interested in other people. We want to connect and share with each other quickly and easily. But social computing as it exists now has many weaknesses that make us frustrated and uneasy. Barriers include multiple passwords, confirming identity, spam, and how to trust sites to which we send our personal information.
David Glazer
But Glazer has found that there is no lack of interest in solutions. What’s next is for applications to be built; he proposes starting with OpenSocial. Such applications must also fit real-world use, and companies must commit to using them. In short, Glazer says, if you want to be a part of the future of computing, get involved now.
Google has thought about using specific author badges based on the expertise and the topicality of the author’s content. In other words, authors might have specific and different badge designs to qualify their own designs, words, and content. In this context, the Author Rank and Reputation of An Author of Online Document designs are connected to each other. On the other hand, the inventor David Glazer mentions OpenSocial which is connected to MySpace which is connected to Google Plus which is connected to Google Author Rank and Authorship Markup.
Ranking authors and their content in the same framework is a Google Patent that was invented by Na Tang and Michal Cierniak. Ranking Authors and their content in the same framework Google patent was filed on August 12, 2009, and granted on April 3, 2012. The patent focuses on ranking scores for a group of users and second-ranking scores for a group of comments authored by the group of users. The main initial diagram of the ranking authors and their content in the same framework demonstrates the process with further details.

The diagram above demonstrates the “user signals” and “graph theory” work together while connecting users to each other. Ranking Authors and Their Comments in the Same Framework tries to aggregate the positive and negative feedback from the users, whether it is only a simple button click or further textual comment. A dislike, like a comment, a rating, or a voting button click can be stored in the comments component database.
There are some initial comment quality signals such as comment length and language model.

The patent design connects comments to the comment authors, and comment authors to each other. Two similar comments can be ranked together, or one of them can shadow the other one by becoming a representative. The diagram above demonstrates different user profiles and how many comments they provided. The design is similar to the Google Sidewiki. Having the interest areas, or understanding which author comments to what with which sentiment is useful to understand the comment quality.
A search engine needs to understand the review structure, and sentiment to review the product type entities or service type entities. Thus, authorship of comments and ranking comments are complementary sections that are relevant to the Google Author Rank.

Above, an author, its sentiment, and its structure are seen. The website, the comment order, commenter, comment date, comment sentiment button, and comment content are clearly given. It demonstrates that Google planned Sidewiki for the entire web with different angles. Later, John Mueller also stated that especially for e-commerce, they also value the total review count, and review content for the product to understand its quality.

Since Ranking Authors and Their Content in the Same Framework Google Patent Design relies on the graph network, the above diagram demonstrates how to connect a comment to a user, a user to a user, and comment to comment for ranking.

Different web pages can connect different users and their comments around a specific topic while complementing each other. A search engine can use the most popular comment terms and phrase patterns as autosuggestion, or a query refinement, along with question generation terms. The specific comments can be used even for People Also Ask Questions and their answer matches.
6. Generating Author Vectors
Generating Author Vectors involves the identification of a specific author from the sequences of the words. Generating author vectors focuses on the differentiation of authors, and author communication styles from each other, to recognize the authors and classify their expertise. Author vectors generate word scores for sequences of words and word scores for a word sequence from a set of word sequences that have each been classified as being authored by the same author.
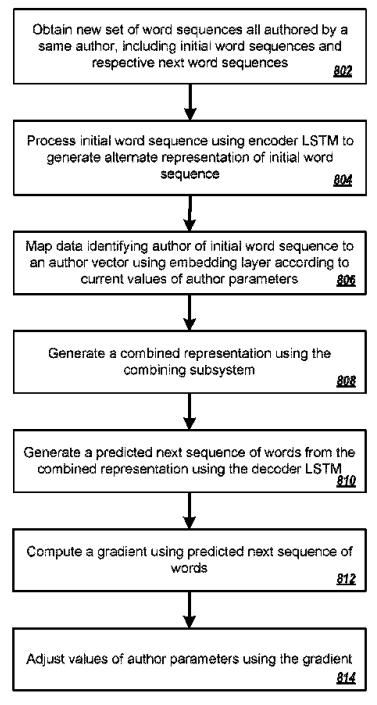
Author vectors are generated via Neural Networks. According to the Google Patent Design for Generating Author Vectors, the Long-Short Term Memory and Encoding structure are used to analyze and guess the next sequences of words. The system is designed to create a threshold system to find specific authors via association and similarity. The 5 key points from the specific patent design are below.
“The encoder LSTM neural network 206 has been configured to process each word in a given initial sequence to generate the alternative representation of the initial sequence in accordance with a set of parameters. In particular, the encoder LSTM neural network 206 is configured to receive each word in the initial sequence in the input order and, for a given word, to update the current hidden state of the encoder LSTM neural network 206 by processing the received word, i.e., to modify the current hidden state of the encoder LSTM neural network 206 that has been generated by processing previous words from the initial sequence by processing the current received word.”
The section above demonstrates how the LSTM neural network is used. By creating alternative sequences of the words, the possible word connections from similar authors are extracted and processed better. LSTM uses Forget Gate, Input Gate, and Cell Gate. These gates help LSTM to filter the related word sequences by increasing the confidence and possibility.
“The combining subsystem 216 combines the alternative representation and the author vector to generate a combined representation for the initial sequence, e.g., a combined representation 218 for the initial sequence 202. In some implementations, the combining subsystem 216 combines the alternative representation and the author vector in a predetermined manner, i.e., the combining subsystem 216 does not include any parameters that have values that are adjusted during training. For example, the combining subsystem 216 can concatenate, average, or sum the alternative representation and the author vector. In some other implementations, the combining subsystem 216 generates the combined representation in accordance with a set of parameters. For example, the combining system 216 can concatenate or average the alternative representation and the author vector and then process the result through one or more feedforward neural network layers to generate the combined representation.”
The section above demonstrates how neural networks can be used to combine the author vectors. Combining, concentrating, or getting the average representation are some useful examples.
“The author vector system 200 can determine trained values of the parameters of the encoder LSTM neural network 206, the embedding layer 206, the decoder LSTM neural network 220, and, optionally, the combining subsystem 216 by training on multiple sets of word sequences authored by multiple different authors. That is, the author vector system 200 can process each initial word sequence in a given set of word sequences to determine the predicted next sequence for the initial word sequence. The author vector system 200 can then determine an error between the predicted next sequence and the actual next sequence for the initial word sequence and adjust the values of the parameters of the encoder LSTM neural network 206, the embedding layer 206, the decoder LSTM neural network 220, and, optionally, the combining subsystem 216 using conventional machine learning techniques, e.g., by back-propagating a gradient computed using the error to each of the components of the system.”

The author vector system and combining subsystem can work together to measure the similarity between different author vectors.
“As another example, an author vector can be used to determine the author of a new set of text. In particular, the system can receive the new set of text and process the sequences in the new set of text to determine an author vector for the author of the new set of text, as described above. The system can then compare the determined author vector with other author vectors that have been computed by the system to determine whether the determined author vector is sufficiently close to any other author vector. For example, the system can determine that the determined author vector is sufficiently close to another author vector when the distance between the author vector and the other author vector is smaller than a threshold distance and the distance between the other author vector and any of the other author vectors is larger than a threshold distance. If the determined author vector is sufficiently close to another author vector, the system can determine that the author of the new set of text is the author corresponding to the other author vector. As another example, an author vector can be used to determine the other authors that are most similar to the author of a new set of text. In particular, the system can receive the new set of text and process the sequences in the new set of text to determine an author vector for the author of the new set of text as described above. The system can then compare the determined author vector with other author vectors that have been computed by the system to determine the other authors that are similar to the author of the new set of text, e.g., other authors that have vectors that are close to the determined author vector.”
The author vectors can be used to predict the next and new sequences of the text pieces from the authors. Author vectors can be stored to guess the specific and future examples of the websites. Author vectors can be used to cluster authors, and also label their personality types.
“As another example, after clustering the author vectors, the clusters can be used to predict basic personality types, e.g., as characterized by Meyers Briggs assessments, OCEAN personality labels, or other personality classifications. In these implementations, the system obtains data classifying the personality type of various authors that have had their author vector clustered and trains a classifier, e.g., a logistic regression classifier, to predict personality types for each cluster using the personality type classifications and the clusters for the corresponding author vectors. The system then assigns a personality type to each cluster using the classifier. The system can then receive or determine a new author vector, assign the new author vector to a cluster, and output the personality type for the assigned cluster as a predicted personality type for the new author. As another example, the system can condition responses on different personality types, e.g., by conditioning responses on a representative author vector for a cluster that is mapped to a particular personality type.”
It is a rare situation that a search engine thinks of clustering authors based on their personalities. For content recommending systems such as YouTube, the author recommendation can be a thing. Thus, the author’s personality can matter for the specific web search engine user. Another aspect is that, rather than recommending the author, it can be used to classify and know the author.

Another use of the Author’s Vectors is that of understanding who is the real author behind the article. Thus, the AI Content generators and the fake author names can be more problematic for the website operators who try to hide the real author behind the article.

“The system receives a new set of word sequences by a particular author (step 304). The new set of word sequences may include, for example, a sentence, a paragraph, a collection of multiple paragraphs, a search query, or another collection of multiple natural language words. The word sequences in the new set of word sequences can each be classified as having been authored by the same author, who may be different from the authors of the word sequences that were used in training the neural network system. The word sequences in the new set of word sequences may be different from the word sequences that were used in training the neural network system.”
The section above demonstrates that author vectors can be used to demonstrate that multiple website ownership can be understood by the author vectors. If two authors from two different websites from the same niche use the same author vectors, these two different websites can be classified as the same website or the same owner website. In the future sections, regarding the author’s identity, expression identity, and website borders, more information will be provided.

Author vectors can be used to generate author reputation, trustworthiness, and expertise scores. Similarly, “Website Representations Vectors” are closely related to the author vectors.
7. Website Representations Vectors
In 2011, a person that I actually admire has written a Google blog post. It is called “More guidance on building high-quality sites”. Amit Singhal has written a question, in this specific blog post.
“Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?”
8 years later, we have seen a similar question from another Google blog post.
“Does the content present information in a way that makes you want to trust it, such as clear sourcing, evidence of the expertise involved, background about the author or the site that publishes it, such as through links to an author page or a site’s About page?”
And, in terms of the author’s identity, there is one more question below.
“Is the content mass-produced by or outsourced to many creators, or spread across a large network of sites, so that individual pages or sites don’t get as much attention or care?”
The second blog post has been written by Danny Sullivan. He also linked the Google Quality Rater Guides. In this case, we will process the “Website Representations Vectors”. And, you can assume that the phrase “in this case” and a sentence that follows with the “will” modal can be included in my own author vectors.
1 August 2018, the Medic Update has changed the SEO Industry. The Medic Update has focused on the medical websites, but it affected mainly other industries too. 5 months later, Danny Sullivan published the Broad Core Algorithm Update-related questions document to help the website owners. Website representation vectors are beneficial for these types of situations. Situations that benefit the website categories, and the expertise signal evaluation.
The website representation vector to generate search results and classify the website is a Google Patent from the Inventor Yevgen Tsykynovskyy. Yevgen Tsykynovskyy is a Google Software Engineer since 2010. He still works at Google, and he is one of the respected engineers. The website representation vectors matter due to four main reasons.
- A source can shadow another source. I will explain this topic in SEO Case Study.
- A source can be representative of the other sources.
- A source can be classified based on the trust and expertise signals on that.
- Classifying websites is a signal of heavy usage of machine learning, rather than rule-based systems. It will be explained in another article.
I will focus on the trust and expertise signals and how Google can classify the authors based on the classified websites. Some key points from the website representation vectors are below.

The subdomains and the main entity of the domain are classified together since they have the same level of expertise. Thus, it is normal to see that the search engine intends the subdomains together with the main entity, but also it doesn’t limit the count. It is an open point that most SEOs can exploit but has not been fixed by the search engine, yet.

The “website-ngrams” are processed in the Topical Authority SEO Case Study, this is one of the prominent points that explain why the site-widen grams are prominent. Because words that appear everywhere on the website can help to classify the specific website further.

The website classification system focuses on the scalar difference by computing the vector quantities between different website representation vectors. These representation vectors can be caused by the design elements or the identity elements.

The website classification system tries to determine different thresholds to compare a website to another or find them similar to each other. Different classification systems can be used for different classified web entities.

The website classification system can determine multiple different authoritativeness thresholds for a website cluster. A website can be representative of the other ones too.

The example above shows that different representations from different feature vectors can classify the different websites under different representatives. These representative sources can take further authority from similar websites. If there are too many similar websites to a specific website, the specific website can be more authoritative and relevant to the specific main knowledge domain. Thus, this helps authors too. What happens if an “author vector” is similar to another author’s vectors? Which one will be the representative? Which one will be the real expert, and which one will be the follower or the similar one? Let’s continue to the website representation vectors to understand their mutual connection with author vectors.
“The score may indicate a classification of the website, such as an authoritativeness, a responsiveness to a particular knowledge domain, another property of the website, or a combination of two or more of these.”
Website Representation Vectors for Google Author Rank
Being responsive to a knowledge domain represents a specific categorical quality. Categorical quality is processed in the topical authority and semantic SEO case studies of Koray Tugberk GUBUR. It is a design from the Trystan Upstill who is a Google engineer and scientist for many years. The website representation vectors are used to differentiate a website publisher’s expertise from another. The authoritativeness of a source and the authoritativeness of an author are connected to each other.
Thus, authors from authoritative sources can be representative of the other authors. But, if a minor-known source has an extraordinary author with a high level of expertise and unique information or an author that provides information gap can reverse the process. An author can provide authoritativeness for the source, and a source can have multiple different borders to be defined and “classified for different knowledge domains with different representation vectors”. Thus, having a proper author vector provides a value for identity resolution and authority assignment. A group of quality author identities can help a source to be a better authority over time. Thus, some websites try to have some quality authors write some articles for their own projects.

Note: When we think that YouTube started to integrate the Google SERP as Google SERP integrates the YouTube SERP, the voices, speaking styles, accents, facial expressions, and face recognition technologies can be integrated into the author vectors. There are many patents for face recognition, image ranking, and understanding human dialogues as machines.
The Website Representation Vectors and Google’s YMYL, and Quality Rater Guides are connected for some sections, thus, we will check some sections in the next chapter.
Google’s Quality Rater Guide for Author Reputation and Expertise
Google Quality Rater Guide is a standardized quality guide for the quality raters. Google search engine performs search tests with the live subjects to understand which web pages are more useful, relevant, quality, and trustworthy. Google’s quality rater guidelines are updated regularly for better inclusive language and helpful directions. To understand the Quality Rater Guides of Google, a person should understand Google’s perspective. The Quality Rater Guides are not for changing the Google algorithm, but to direct the Google algorithm’s direction with the live feedback from the human searchers. In this context, the author’s authority and reputation is a sub-topic in the quality rater guide. In this section, this information will be shared to make the author vectors, and website representation vectors more concrete.
“Having data from multiple sources such as patents, Google spokespersons, interviews, news, practical SEO Projects, and Case Studies, along with Search Engine documents is the best way to understand a search engine, their priorities, and perception of the open web.”
Koray Tuğberk GÜBÜR

The reputation of the website and the creator of the main content is a good differentiation between the website and the owner of the main content. In other words, the authority of the website and the authority of the author are two different things from each other. Thus, making the website authority and author authority differentiation is relevant to the author vectors and website representation vectors. The “Centerpiece Annotation” and “Main Content” are relevant to each other. Martin Splitt from Google explained that there is something that Googlers called “Centerpiece Annotation” for explaining what Main Content is. Centerpiece Annotation helps search engines to locate the main content, main entity, and purpose of the web page. If the centerpiece annotation is connected to the main content, they can weight certain sections of the website heavier and better.
Centerpiece annotation and main content creator are connected to each other. From time to time, a search engine might not realize that the name on the web page is not the author of the main content. The owner of the website and the owner of the main content, website, and brand connection can create different types of weights and prominence for the articles.
The reputation of the main content creator can be understood from the sections below according to the Quality Rater Guides.
- The About US Page can give the identity of the specific organization.
- The Homepage can give the identity of the organization.
- The author, or the owner of the material section, can give information about the main content creator.
- The Social Media Profiles can give the organization identity.
- The third-party, uncontrollable review websites can give the reputation and identity of the organization.
- Customer reviews can give the reputation and identity of the organization.
- Corroborated web pages from open web for the author identity and brand identity are used to understand the web page’s quality and content reputation.
- The user search behaviors and social media platform shares and data can be used to understand the overall quality of the main content creator and the website.
- The difference between the main content creator and the website identity reflects the harmony between them.
- The difference between the main content creators and the website identity can be united with the combinations of web entities such as “author 1 – website a”, “author 1 – website b”, “author 2 – website 1”, and more. These combinations can create different types of reputation scores and cohesion. If the cohesion is higher between the main content creator and the website, their evaluation can be done with a higher confidence score. But, if a website has 900 different content creators, and the “author 1” has only one content that does not serve many queries or does not have any information gap, it might be evaded for further evaluation.
- The information gap the author provides is prominent. Information Gap processed in the Semantic SEO Case Studies of Koray Tugberk GUBUR. The Information Gap that comes from the author can give him authority. And, authority can be seen, understood, and shown its effect over time. Thus, the information gap effect can’t be used for quick SEO A/B Tests. This is a valid statement for all the E-A-T-related concepts in SEO. It is an improvement for the “Complex Adaptive Systems” that check multiple prominent points that align with each other. It takes a longer time than only “CSS Compression”, or the “Title Changes”. Furthermore, it might require multiple Broad Core Algorithm Update changes.
- In the next sections, we focus on “finding the homepage”, and “finding the true identity, and responsible person from content for evaluation of reputation and website borders”, these combinations and reputation understanding algorithm designs should be remembered to evaluate the content pieces further.
Some notes for the reputation understanding of Google for persons and authors are below.
- Google knows that a single negative review, or multiple negative reviews, do not harm the reputation. It is normal to have some negative reviews. The reviews from different perspectives can show the different corroboration possibilities, and even some reviews from Google Business Profile (Google My Business) affect how the source is perceived and what is the main knowledge domain of the source. The GMB or GBP reviews can rank for SERP, and they can show the prominence of the specific web entity for a knowledge domain.
- Google knows that a website organization can sustain the website, while every creator is different. This is also a valid statement for the “authors of comments”. The author of a comment can affect the authority of the comment, but not the main content of the web page, or the other reviews on the specific web page. Thus, even a single YouTube Comment Author or a single Reddit Post comment should be evaluated differently. Being positively received on Medium, or Quora doesn’t mean that it will benefit the reputation if all the reviews come from the same people, or accounts that are not authoritative.
For this perspective, Google puts an example below.

From Q&A Websites to the Review Websites, or to the Wikipedia, Video Publishing Portals and news, or knowledge domain blogs, if the author and the website are mentioned together, or separately, but with a good sentiment, it signals that the specific web entities are authoritative.
Google and Corroboration of Answers from Open Web with Author Identities
Google Authorship Markup and Google’s Article, Author, and Owner connections in the Structured Data are useful. The main thing here is that Google Authorship Markup, and Google’s Article, Author, and Owner connections are not the same things. Article Structured Data from Schema.org is used to state the article’s topic, content, author, or even keywords, and subsections. The article structured data of Google is the Google’s perception of the article structured data. Since Google’s perception of the specific structured data types is different, we also have a Structured Data Testing Tool from Google, and also Shcma.org. They can show different results based on these types of perception differences.

The article structured data can demonstrate the same person over different websites as the author of the same article, highly similar articles, different articles from the same topic, or articles from different websites for the same, and similar topics. These corroboration attempts are called “entity-reconciliation” by the search engine, and it showed its effect on the SERP for the Authors or other types of artists. Article structured data is prominent to corroborate the author’s identities. Thus, in the coming sections, the “author identity and expression identity” will be processed.
Entity-reconciliation is a prominent task for the search engines to differentiate the different profiles of the authors or authors with the highly similar profiles. For example, the Barry Schwartz name appears for the Journalist Barry Schwartz in the SEO industry, and the Psychologist Barry Schwartz. These are two different entities, of the same type, but different occupations. An article’s topic, or a comment’s topic, can be related to the specific entity according to the overall topicality. A negative review should only affect the specific entity rather than also the others.
Entity-reconciliation is prominent to understand the two different profiles and authorities of the same author. An author can use different expression identities for different topics. The expertise and the sources that mention the specific author can be different, too. In this case, The expertise and the authority profiles can be divided into different author profiles. For example, Koray Tugberk GUBUR is a Holistic SEO Expert, but he is also an expert in bodybuilding. In this case, reputation can be shared but authority and expertise will be divided for the specific entities’ content network.

Google follows the links from different author profiles to understand the specific website owners or the main content creators. The author information including structured data can help an author to make the search engine recognize herself/himself faster, and since the topicality will be provided from a second data vertical, the search engine’s confidence score and overall grasping will be improved for the author. In this context, the author entity-reconciliation, author structured data usage, author name, and profile similarities, or the author’s multiple profiles should be considered in a parallel way with the data that can come from structured data. The website-author tuple variations can overlap with the specific sentiments, quality, expertise, and reputation over time.

Structured Data is not used only for web page documents, segments, and content. It is used for emails too. An email can be used by the search engine to understand which email is spammy, or which one is relevant to a topic. A search engine can understand a user’s interest areas and personality from email subscriptions. A search engine can evaluate the reputation of an institution from the Emil newsletters, and users’ feedback too. Thus, reputation is a multi-vertical feedback collection from different ambiance platforms.

Above, you can see Justin Boyan’s patent design for selecting the specific web entities from the web pages to describe them, whether they are reviews, books, or authors.
Below, you will see how Google Patents and the Google Blog align things with each other.

This is directly the “data-highlighter” tool’s purpose. But, this doesn’t end here. The main purpose of the data-highlighter wasn’t only to help users to mark specific web page sections for Google’s perception. It was forgiving enough level information for improving the stability of the search engine decision trees, that’s why it says “models” or “training models”. For example, Google Captcha uses user feedback to train its own data-set and understanding. In the same way, the Google Data-highlighter tool used the structured data choices on the web pages to understand which web page segment does what. The search engine also uses the “Google Docs”, or “Google Meets” and other data gathering tools, that’s why they are free. Because data is the digital oil of our age. And, Google has the most data for every type of search engine task thanks to its multiple vertical ambiance optimization projects.
The prominence of this data-highlighter tool for authorship, and authorship understanding is that most of Google’s reflexes come from the data and the models that are trained from this data. How many authors appear in a content piece, or who is the author of a comment, how many comments should be gathered, used, and understood following the quality of the main content, or how to canonicalize different author names under one, how an author can represent others. Most questions are answered via Justin Boyan’s design, tool, and announcement.

After this explanation, things started to change. Google started to understand the authors, and other types of entities, via different web page segments. The “centerpiece annotation” is necessary to understand via the data-highlighter tool, because the search engine can relate products to the product grid, or to each other, and different web segments. The names, dates, and content owners on the web pages provide a better understanding of the specific website’s, or author’s topicality.

Thus, corroboration of author identities, articles, and quality from the open web and understanding text, text blocks, content items, and structured data help each other. In the next sections, we will focus on Author Ranking with Google Authorship Markup. Justin Boyan focused on other machine learning-related tasks for the Search Engines as well.

These researches are prominent because RankBrain was nearly the first machine learning used algorithm by Google. And, even it was “half-machine learning” technology since it was using supervised learning. Thus, between 2011 and 2013, these researchers show that their perspectives on the new methods were clear. From the VIPS Algorithm to the web page segmentation, indexing of web pages, and corroboration of answers, this machine learning early age of the search engines and structured data, along with author entity recognition are connected and prominent concepts for understanding today’s SEO, and search engines.
Google Authorship Markup and Google Author Rank Relation
Google Authorship Markup is a product and structured data model to understand the author of specific content. The Google Authorship Markup and Google Author Rank are relevant to each other because Search Engines can recognize authors. Most of the time, the Google Authorship Markup has been seen as “The System and Method for Confirming Authorship of Documents”.
On August 28th, 2011, Erich Schmidt and Andy Carvin performed an interview, and they concluded the section below as a quote.
“But my general rule is people have a lot of free time and people on the Internet, some people do really, really evil and wrong things on the Internet, and it would be useful if we had a strong identity, so we could weed them out. I’m not suggesting eliminating them. What I’m submitting is if we knew their identity was accurate, we could rank them. Think of them as an identity rank.”
Interview of Erich Schmidt and Andy Carvin for Google Author Rank
The Google Authorship Markup was announced on June 08, 2011, in Google’s Blog by Othar Hansson. If you are a careful reader, Othar Hansson is announced second time in this article, because he is the inventor of the System and Method for Confirming Authorship Documents.
The announcement for the Google Authorship Markup is below.

The Google Authorship Markup is used with the “HTML5” rel=”author”, and “XFN rel”=me”. XFN is the XHTML Friends Network, which is an HTML microformat developed by Global Multimedia Protocols Group. On 16 April 2012, Google announced Authorship Profiles for German, Italian, and Indian internet content. This announcement contains the Google Plus as below.

The author of the post Uli Litz is from Google Search Quality Team. And, his Google+ Profile only talks about Google+ as below.

These sections are prominent to show how Google Engineers are connected to each other, from a patent to a search quality measurement. Othar Hansson says that “Great content comes from great authors”, and they want to help great authors to be more explorable.
Google Authorship Markup and Google News, Social Media Comments
There is a reason that Othar Hansson mentions the New York Times or CNet for Google Authorship Markup because it is a clear signal for the news media publishers. Google News and Google Discovery are still connected to Social Media in terms of appearance and engagement. In the past, Facebook Comments were a popular method for ranking websites too. Today, Google always says that they don’t use social signals or social media comments, but still, they index them, and they use these links for exploration. Matt Cutts even said that they try to understand the Twitter Profile Links and their prominence to the users. In this context, MOZ has published several articles related to Facebook Comments and some other Popularity signals.

Popularity and Authority Rankings are connected to Google Authorship with these discussions. But, Authority and Popularity comparison for a search engine ranking methodology can be done in a different article. Google Authorship Markup and Google News are connected to each other to understand the most quality authors and their news articles. Today, most journalists started to have different Brand SERP samples and designs. The Popularity and Authority Ranking comparison can be processed in Authority Ranking Google Patent (Susan Dumais is one of the inventors), and Dynamic Reranking of Search Results Based upon Source Authority Google Patent Design for another section. Below, you can see a section that compares the Facebook Shares to the Ranking Correlations on Google.

Google News and Google Discovery are correlated with Social Media Engagement, thus even some news media publishers use Twitter and Facebook botnets to improve the possibility of visibility on the Google platforms. Google News and Commenting along with the social media activity are connected to each other in terms of understanding the Authors’ quality and authority. But, authority, popularity, and social media-related Google Designs are also different verticals from each other. In the context of the Google Author Rank and Mark up, the prominence of Facebook Comments in the past, and Google News Authorship, along with the understanding of authors, and their articles as author-article pairs are prominent.
Authorship Markup and Google’s Knowledge Graph
Google has a Product Graph, Topic Graph, and many other related entity types’ graphs, like “Landmarks”. Google’s Knowledge Graph has two main benefits for author recognition. Collecting all the web pages about the author’s profile, and articles, organizing the author’s entity identity directly relevant to a specific book, occupation, or topic. For example, my name “Koray Tuğberk GÜBÜR” is associated with two different entities. One is “Koray Tuğberk GÜBÜR – Consultant,” and the other is “Holistic SEO & Digital – Marketing Agency”.

When I search “who is Koray Tuğberk GÜBÜR”, I see that a web answer states, that I am the owner and founder of the specific company entity.

My face is directly there, and I am “an Author on Search Engine Journal”. Let’s check the same thing for different authors. “Leo Tolstoy” sample is below.

And, now, another author. “Noam Chomsky”.

The main difference between the two different authors Brand SERP is that one of them is from our century, thus it has “news”, “education videos”, “videos”, and “movies”, while Leo Tolstoy is from another century, and most of the videos, or news do not necessarily include the Tolstoy, but only his a few words. Thus, according to the author entity’s existence, and life-cycle in the digital content production, the brand SERP design changes. It affects the entity association between other author entities. But, the main benefit of the Author Brand SERPs is organizing the entity identified as stated in the “Erich Schmidt’s interview” as “identity rank”.
On Google SERP, we can calculate the distance between “two concepts”. How about the distance between two author entities? How are the “related entities” listed? Or, how are the entities ranked in the search console? Does it check the co-occurrence? Or, an entity is an attribute of another within a triple? Like in “topic graph”, “author graph” helps to understand the open web further. An author’s main topic can be seen as a topical connection between the specific topical entries and the author’s entity. A book from the author can be attributed to the topic, and other websites can come closer to the specifically related queries in terms of relevance, and authority.
Helping authors organize their own Brand SERP with their own artwork helps Google to achieve Google Knol, Answers, Talk, Sidewiki, and Plus at the same time. It helps to see “Authorship” beyond a simple markup, and it expands it to the author’s fingerprints on the open web within entity-oriented search understanding. Author Understanding, Recognizing, and Organizing should be seen as one of the main tasks of a search engine. In fact, there is a surprise sample for that.

The document below explains the necessity of the PageRank as an “important signal” and the necessity of contextual search. The document is from 1997.

The document below is from 2000. It focuses on patterns of the open web. It belongs to the other Google Founder, Sergey Brin, while the previous one belongs to Lawrence Page.

The document focuses on extracting patterns as tuples, and it tries to do these from an extensive amount of organized information.

The example above shows one of the possible methods to extract patterns for tuples.

The section above explains how to take “book-entity” pairs. In this case, the books and the authors were/are the first step of creating the semantic search engine for Google Founders, because they focused on the patterns on the web from book-author pairs. Here, Sergey Brin tries to extract thousands of book names and author names as pairs, and he explains that it is hard to understand which author is who, and which book is real or not.
In this case, Authorship, and true expertise, are relevant to the PageRank. An early Google Search was for “academicians”. The “citations were the links”. The citations were coming from the authors of the academic paper owners. Because the early days of the internet were solely for academic purposes. In this case, the early days of the search engine Google were only for author expertise and the author’s article’s prominence. Both the semantic web creation and PageRank design focused on authors, books, papers, and citations.
Thus, the Authorship Markup, Brand SERP, Author Graph, Identity Rank, and all the other Google products like Google Plus, Knol, Sidewiki, Answers, Talk and inventions like Agent Rank, Content Author Badges should be seen as the next steps of the early days of Google. Authors and Books were the first entities, phrases, and queries for the Google search engine. In the future, we can talk about the Google N-Gram Viewer and 846 million words from the BERT Dataset that comes from Google Books with this context.
How to Use Ahrefs Author Finding Tool?
Ahrefs’ Content Explorer provides a Top Author Tool for the SEOs to explore new experts on a topic. It is a useful technology to find authoritative sources for a specific topic, and create new useful cooperations for branding and PR. Thanks to an Author Finding technology, an SEO can compare the articles’ performance to each other from different authors to understand which author is better for his own topic. To use the Ahrefs’ Author Finder, click on the content explorer.

Make a search for a topic.

In the content explorer, check the right side for the “Top Authors”.

Click the “View Top 100”.

The Top 100 Authors section demonstrates the names of the authors, their profile links, how many pages that they appear on, what their activity has been for the last 30 days, how many websites they appear on, what is the total number of traffic these articles get, and many more things. Below, you can see the benefits of these dimensions.
- Author Name: The author name is the label of the author. It is the most important identifier of the author. Author name can be a simple nickname that confuses data collection systems, such as “admin”.
- Twitter Handler: Twitter Handler is another identifier for the author. A search engine can also check the PageRank of the Twitter Account, hashtags, bio, tweet count, answers, media, and interactions to see the account’s main topical entries and overall authority in an audience. There are certain algorithms that label people in an interconnected social media platform. Entity-reconciliation is another topic that is relevant to the author identifier links on the web pages.
- Total Pages: Total pages represent the pages that have the author as the owner of the article. An author can be a “co-author”, or just the “receiver”, in this case, the search engine systems can open new dimensions for the author entities.
- Last 30 Days: Last 30 Days show the activity level of the specific author. An author can have 9999 articles on a topic, but if they are from 30 years ago, they might not be an active opinion leader. Of course, if the topic is “philosophy”, still Aristoteles is an opinion leader, but if the topic is “plastic injection molding”, the situation changes.
- Websites: Websites represent the different sources that have the specific author. An author can be cited on different web pages, but if there is not enough source diversity, the search engine might not corroborate the answers from the web.
- Total Traffic: Total traffic involves the author’s web pages’ popularity. It can signal success or the specific topics’ popularity in terms of search demand. Non-popular topics do not mean “non-quality” authors.
- Traffic Value: Traffic Value shows the monetization value and overall competitiveness of the specific author’s articles. It is correlated with the competitiveness of the topic, and the traffic value of the authors’ articles.
- Avg. Ref. Domains: Avg. Referrer domain count involves the domains that link the specific articles of the specific author.
- Language Dimensions: Language dimensions include the languages of the web pages that the specific author writes in.
- Page Dimensions: Page dimensions include the web page detailed information for the authors’ published web pages.
- Website Dimensions: Website dimensions give further information about the websites where the authors are located. A website can be a quality source for a topic, but the author from the source can focus on another topic. Thus, the topicality can affect the authority’s benefit. If the source is a general authority for many knowledge domains, then still it can be an authority signal, even if it doesn’t provide relevance.
- An author’s content can have its own “authorship sign” with the expression identity. Even if the content is stolen, still, the author’s main website and main connected brand entities can have more benefit from the rankings. A search engine can protect the authors’ content from plagiarism with the authorship sign. Sometimes, this is done with manual penalties, sometimes it is done via “content hashing” and “string similarity algorithms”.
Ahrefs’ Author Filter with Data Manipulation
Ahrefs has many filtration options in its own content explorer. But, for the Author Finding, the main benefit is to find a real expert author for a topic, Ahrefs provides the “author filter”.

For this example, I have used my own name, “Koray”.

And, as you can see, Ahrefs has 16 different web pages from my articles that are relevant to the “SEO”. Ahrefs says that the “Topical Authority SEO Case Study ” is the best sample article from me. We can also see that they cluster “Koray Tuğberk GÜBÜR ” and “Koray Tuğberk” as different. We also see that they collected my Twitter Handle too.

Now, I have used Dear Lily Ray’s name. And, you can see the articles below.

And, we have all these results from Lily Ray. Let’s say, I want to see one website as an example per article. Click the “one per domain”.

If you want, you can exclude “homepages”, and “subdomains” too. Because, sometimes, accidentally a person can be registered as an author on the homepage via structured data, or a similar expression. And a search system can infer that the person is an author. Subdomains can even have “test servers”, and index them accidentally. To prevent any “noise”, the subdomains can be filtered out. Another good part of the “author” filters in Ahrefs’ Author database is that being able to use multiple filters together.

Here are the filters that I have used for Lily Ray’s articles.
- Referring Domain Count is between 10-and 20.
- The domain is “sistrix.com”
- The author is “Lily Ray”
We see some articles from January 2021 and January 2022. Since I follow Lily Ray, I know that these articles are for analyzing the “Winners and Losers of the Core Algorithm Updates”.

And, here are the results. Let’s do a similar search from Google.

And, we see that Google also ranks the same pages as most relevant and prominent. Thanks to Ahrefs Toolbar, we also see their query count, and referring domains. With Google Advanced Search Filters, we can state where we want to see phrases “Lily Ray”, like “anchor text”, “title”, “URL”, and “body text”. For now, the Advanced Search Filters do not work for a specific “structured data element” such as “author”. But, the “Custom Search Engine” design of Google is able to filter search results based on their Structured Data Usage, and “Topicality”, or even specific structured data properties. Maybe, in the future, Ahrefs, or any other tool can do it.
If you want to use Custom Search Engines with Python, read the related guide and tutorial.
Google’s Site Definition and Author Connection
Google’s site definition is different from normal life. According to Google, a website can occur from multiple sub-sites. A domain and subdomain can be a single website, or they can be different websites. Different authors can be interpreted as different websites, even if they are located in the same domain as their articles. Different web page designs, topicalities, and categories can signal different websites too.
This topic is relevant to the “Inorganic Site Structure”. Site structure and “website boundaries” are prominent to understand a website before ranking it. Thus, Authors’ existence on a website is prominent to understand what a website is, and what a website is not. Different segmentation of website structure can signal multiple websites’ existence in a single domain.
Old blackhat methods involved subdomains to use as a source of “external link”. If a website design was too different from the actual main entity, it means that the website will have external links from its own subdomain. Another implementation of the inorganic site structure was hiring the subdomains. Since the subdomains get better rankings thanks to their authoritative main domains, it would be perfect to hire a subdomain. Imagine that you pay a fee to the New York Times, as an owner of a subdomain. These “irrelevant subdomains” later are de-indexed. Search engines have even published research about finding the “true homepage” of a website based on the PageRank or based on the navigational popularity of a specific web page.
Thus, having multiple website sections and boundaries is possible. Why is having boundaries on different website sections relevant to the authorship? Different authors on a website can signal different websites. A search engine can decide an authority score based on the average trustworthiness of different authors on a website. Or, a search engine can rank a source higher thanks to an author, while it can rank some other sections lower due to another author’s identity.
Author articles and general non-authorship articles can signal different website segments.
Every author can be perceived as a different website within the same domain. For example, Search Engine Journal is a huge website, and every author has different expertise. They can feed each other trustworthiness, and some of them can boost the source’s trustworthiness even further.

When it comes to understanding search engines, I find Matt Cutts era Google, and Microsoft Bing more open, honest and trustworthy in terms of their “statements”. Above, you can see a blog post from Microsoft Bing, relatively updated, related to the website boundaries. Out of context, that’s why using a consistent menu, logo, and brand design is necessary to prevent inorganic site structure.

The example above represents the same website as different domains.

The example above represents the same website as different domains. Cross-domain canonical or hreflang usage is relevant to the website boundaries. Authorship and website boundaries represent different types of SEO intersections.

This is another example from Trystan Upstill. It is also interesting to find a current Googler’s research paper from Microsoft.com before Google-related sources. Query-independent Evidence in Home Page Finding defines a homepage and explains what are the methods to find it. Homepage Finding is prominent because a website is defined by its own identity and boundaries from there. In this case, different website sections can have different homepages. For example, an author profile web page can be a second homepage for the articles of the author.
Some Example Effects of Website Boundaries with Authorship
Some example effects of the website boundaries with authorship are below.
- A website’s authors can be perceived as different website sections.
- Different authors can create different website boundaries that divide a website into multiple websites.
- An author’s articles from multiple domains can be perceived as the same website.
- An author’s overall popularity, prominence, and success can affect the other websites’ success.
- An author’s activity of publishing new articles can raise the specific authors’ other old articles.
- An author’s main profile, and most closely related websites, can have the proper effect from the author’s authority or non-authority.
- An author’ branded queries can have multiple “author website homepages”.
- An author’s website (articles from multiple domains) can have different preferential homepages to order different sources.
- Authors can be clustered based on their expertise level, but also expertise topics. A source can have more authors from a specific topic. Thus, authors from that specific topic can be taught as the main authors for the website.
- A source’s topic and author’s main topic should match. If not, the author’s article might not enter its own “multiple domain website” definition.
- Search engines can use social labeling for collecting the closely related authors to each other like it is done for especially the product graphs.
- Search engines can cluster authors based on their main topic, and profile, occupation consistency.
- Search engines can use sentiment analysis to understand what authors like, who likes the author more, and why.
- The first appearance of the author for a topic from a specific source, and the last appearance from the specific source for the same author, can represent the “lifecycle of the author” for that source. Based on the timeline length and frequency of publication, specific articles and sources can be dropped from the author’s website.
- Specific authorship can represent authority if the author’s publication date is too long. The author can be seen as a possible opinion leader with other correlated quality signals such as social shares, sentiments, and responses.
- Authors’ articles’ citations, and existence on different other sources such as Google Scholar, Google Books, Amazon Books, Goodreads, Wikipedia, Wikidata, Crunchbase, Ted Talks, Spotify Podcasts, iTunes, Google Podcasts, and more, represent the author’s popularity and weight on the topic.
- Authors’ articles referring domains, referring pages, and also “referring authors” signal the authors’ authoritativeness. In this case, if an authority author cites your article, it means that it is not a “referring domain”, but also a “referring author”.
- Author links can create an author graph, and seed authors for a specific topic. Author links signal the authors’ relevance to each other. Authors can be ranked based on their own popularity between the citations.
- An author can have multiple names. And, multiple names can be written with different permutations or different pronunciations. In this case, a search engine might have a hard time performing a perfect entity reconciliation.
- A source can be authoritative for defining the authors. These sources appear in the Knowledge Panels on the SERP to define the specific author, more than others. These sources are seen as seed sources for these entities, as a data repository. Authors can use these sources to define themselves in a half-controllable way.
- Authors’ articles can be seen from click-through data. The multiple clicks, search behavior patterns, the featured snippets, people also ask questions from the authors’ articles, authors’ name searches, and brand SERP represent the authors’ success or deepness on a topic. For example, when it is about “parallel universes”, you might not click a link even if the author is from Cambridge University, because you are not an expert on the topic. Thus, certain types of users’ behaviors can have more meaning than others. That’s why user clustering and their interest areas, along with the interesting topics are prominent to see which click, from whom, means what.
- Author profiles from multiple sources from the same topic can help the author recognition process by linking all the profiles to each other.
- A search engine can use “voice” and “face” detection to recognize an author from different content types, such as audio and images.
- An author’s phrase patterns can be used to define the author’s expression identity. Even if a web page uses a fake author profile name, or picture, search engines still can understand who the real author is. For example, when I tokenize the entire corpus of my own website, I see that the most used words are “SEO, Google” and then the “also”. Search engines can create enough levels of detailed co-occurrence matrices to understand which frequency, which phrase patterns, what kind of part of speech tag, and even average word per sentence, and other types of expression metrics can be used to see my “expression identity”. These are called “author vectors”.
- Using fake profile pictures, or fake names for the “teams”, or “authors” sections can destroy a website’s entire brand identity. Since the 2009 Vincent Update, Google ranks the “brands” more and more, and ranks blogs “less and less”. Not having a real-world entity as the author can devastate the real-world entity profile of the website while decreasing its overall rankability.
- The same article from the same source can rank differently based on the author. Internal links and external references to the author’s identity can affect the initial ranking further. But, expression identity and author identity should match. This inconsistency can affect the rankings negatively further in the future during a re-ranking event.
- In certain situations, a brand entity can use its own identity as the “author”. In this case, the author entity will have multiple expression identities. An author doesn’t have to be a person, but it can be an organization like NASA or even Google. Thus, writing guides, and certain phrasification methodologies are beneficial. In this case, a “Brand-entity” can be an “author entity”. And, an “Author-entity” can be a “brand entity”. In this case, website boundaries will have two different definitions and meanings. When someone searches for the “brand name”, it can also give the “author page”. If the brand doesn’t use its brand name as an author for other sources, it might be convenient to assume that the brand entity is the main profile. Thus, having a “CEO” as the author can help for further authority building. I use “authority building” differently than “PageRank hoarding”. But, it is a long, and discussion.
Expression Identity and AI Content Writers
Expression identity represents the identity of the specific author’s phrase patterns and expression style. An author can have multiple identities for expressions, even from year to year, or topic to topic. But, most of the time, these differences don’t happen directly in one day, it takes a longer time, and big changes in the expertise, or the personality. Expression identity can be extracted from the sequence of sentences from the authors. If a search engine user uses the query “what is X”, there are endless possibilities to answer the specific question. Thus, an author’s answer and different word vectors, word proximity, and word and sentence structures are used to differentiate authors from each other. And, AI Content Writers do not have enough level of Expression Identity variation. Imagine that, Author A starts using AI Content Writer. It is clear that the Expression of Identity will change. Author A with Expression Identity B is an inconsistency. But, the problem doesn’t end here. What if 150 more Authors have the same expression identity? And, are all these topics different? Does it mean the same person is an expert on 150 different topics with 150 different internet names and different social media profiles and real-world existence references? Today, there are “AI Content Detectors” to differentiate human-generated content and AI-generated content from each other. AI can predict the next word in a sentence or a corpus easily via the dataset that it has. Thus, AI Content Detection with AI is pretty easy. But, humans are more unpredictable than machines, since we have complex brains and more than 100.000.000.000 neurons in our thinking organs.
I wanted to touch on the Expression of Identity and AI Content Writing possibilities. In the future (at the moment too), we have, and we will have many content pieces for the same topic or the different topics. Search engines are able to filter quality authors from non-quality authors, as real authors from fake authors. When we unite the “website boundaries” and “authorship effects with website boundaries” with the examples that I have given, you can find many negative and positive effect possibilities. An author can blend its own expression identity with AI Content, while Google tries to filter out AI Generated Content, or directly scraped and “paraphrased” and “blended with unique sentences” content.
In the future, “Relevance Radius”, “Relevance Attribution”, “Similarity Thresholds”, and “Content Hashing” concepts will be processed with the concepts of authorship and “web bloating” with some SEO Case Studies to explain this situation further.
Last Thoughts on Google, SEO, and Authorship
Google, SEO, and Authorship identity, quality, and concept are intertwined with each other. Google’s Authorship, and Social Media Platform plans have existed for a long time. The latest Google Knowledge Panel Designs directly for the Authors is also a signal that Google didn’t forget its previous plans. The Brand SERP and Knowledge Panel Optimization are relevant to Google’s Authorship Reconciliation and Presenting. Google always prioritizes the queries based on their prominence and popularity. Google focuses on singers, writers, authors, and actors because they are relevant to many queries. Query-Entity-Phrase associations, inferring entity attributes from the queries, or “defining the queries”. Because “author entities” are relevant to the specific queries. And, an author’s connected query count, and the success of the articles from the author for those queries can create new “context vectors” with “author identity”. Lastly, it should be noted that an authoring entity doesn’t have to be a human. Cooperation can be an author too. In this case, “multiple expression identities” are not a problem as long as the authorship is consistent in terms of expertise level and certain writing guides. And, unique AI Writers can be programmed to protect the authorship identity with expression identity. But, whatever happens, a Holistic SEO must always protect the state-of-art level of search engine understanding and optimize SEO Projects for multiple possibilities, angles, and scenarios. Thus, using an AI Content Writer with unique phrase patterns, configurations, and datasets while keeping it controllable and quickly changeable via “algorithmic authorship” principles is the best possibility to create better authorship and expression identity.

- SEO for Casino Websites: A SEO Case Study for the Bet and Gamble Industry - February 5, 2024
- Semantic HTML Elements and Tags - January 15, 2024
- What is Interaction to Next Paint (INP), and How to Optimize It - December 7, 2023


I print your articles and file them. Because I think that these unique and labor-intensive articles should be read by touching and taking notes. Definitely keep posting.
This is an OUTSTANDING article! I always enjoy reading your stuff!
Thank you so much, Morten.
Hi Koray,
thank you very much for this detailed article! I’m thinking about using AI-generated content more often in the future, primarily AI-generated text. After your article, I’m now a bit unsure about the author assignment for AI-generated texts. What is the ideal way to rank on Google with AI-generated texts? Who do you take as an author? Do you have any tips?
Many thanks in advance
David
Hello David,
Thanks for your comment.
You can try to train your own language model with your own understanding and parameters. There are NLP Engineers to make AI Content Generators unique. It takes time and requires big data, and high levels of computation, but it is possible to do.
And, a cheaper way to make AI Content original is by using a human editor. If you find more configurable unique AI generators, they would help you as well.
Phenomenal article. Just noted several practical real-world steps to add to our process to strengthen the author entity further. Also, some ways to further tie things together around the person as the author. Your dedication to the nuance and details is appreciated. I saw the 77-minute estimated read time and was like “Oh boy, here we go!”
Thanks for your kind words, Jordan.
I will do focus on author page too. I never think author page will do more impact.
Thanks for the details guide
Thank you so much, Rama!
Where can I, as a simple google user, retrieve this data, and in what format Google presents this information?
Hello Daria,
Google doesn’t provide a Google Author Rank or quality score. But, Ahrefs can be used as an authoritative author for certain topics, in the last section of the article.
The content is very informative but too long to read.
Thanks for the feedback, Anup.
This content is very nice!
Thank you, Maria.
“Bilgi ihtişamdır ve sahibini muhteşem kılar.”
Ağzınıza sağlık.
Hi!
Is it enough for an author to have his social networks that Google will identify him as an author? Can an imaginary author be used if the articles are written by third-party copywriters?
I suggest you use real authors.
And, Social Media Accounts can be used for authorship recognition.
Hi Koray,
This is fantastic. I’ve spent far too long reading it than I should have, so I will be pocketing it for later!
I had an intuition that Google will place more emphasis on individual authors over time, as we see corporate branded content becoming a bit stale. So these findings will be even more important.
Do you feel that this will be the case?
Thank you, Benjamin.
And, yes, I feel that this is the case.
Hi Koray, when you go to a new company, sometimes you assign to your profile randompieces of content not created by you (the ones without any real author, for instance).
It could be a BAD point for your reputation?
Thanks a lot!
If the website is prominent enough, and the previous author is a popularly named entity, it might be bad. If the website is not a prioritized source, no, it won’t matter that much.
Thank you for all your amazing work. Please ignore anyone that says this is too long or technical to read. We are very lucky to have someone like you giving us such excellent information. Those people that think this is too long or technical do not really want to understand how Google works, or what you are doing with that content. In fact, this piece itself is a perfect demonstration of all the principles of SEO, not just in the content itself, but in the execution of it (image SEO, TOC, heading structure, etc).
Please let me know when your SEO course is coming out and an approximate price. I will be the first one through the door. Thanks for all the amazing information. I am making it a daily habit to study your work , as well Bill Slawski’s content.
Thank you for your kind words, and I will!
Quick Question Koray.
Where are these images hosted? GMB profile?
https://lh4.googleusercontent.com/cyTczcawmWtaoXmN_uanTJrVEEmTg-ivd6qdqReyT8KvGQ_XDYj2NKM01d6H-8CtYaDX_2ViI7QAFDUSwe96Tg89rSM20Yi90cHVVp1MTAm24EQX7Cnc-lbdFnXw-MmQxiMf7lSV
Hello Demetre,
Thanks for your comment, it means a lot to us. Googleusercontent comes from Google Cache.
Hi Koray,
This is a very interesting read and thank you for all your hard work and research on it. I’ll be following your stuff very closely in future.
One piece of feedback which, I hope you’re open to(?) is that there are a lot of statements which don’t seem to have any sources / evidence backing them up listed….For example:
“Google Answers is abolished by Google due to the high level of web spamming, and the usage statistics. But, Google didn’t give up on its social search engine purposes.Thus, Google Answers and Google Talk are connected to each other with Google Author Rank.”. (No evidence that Google Answers are connected to author rank).
And …
“Google Talk provided a vast amount of data for the dialogues, and the conversations between humans to understand the human language with Natural Language Processing further.” (No evidence this was the case).
Again, I really appreciate your work and I don’t want you to feel that I’m trolling 😀 maybe I’ve missed the references / citations / sources(?) section.
Thanks again.
If you read the “Social Search Engine” section again, you can understand it. No one can enter your brain and connect the dots for you, and no one needs to draw a bird and write “this is a bird” under the drawing, because it is obvious to the preceptor. Google won’t give you any kind of direct information, so you can use “citations”, and evidence come from the 20 years of progress for connecting audiences with expert authors, whether it is Google Answers, Google Plus, Google Knol, Orkut, etc. Google Talk reflects a search engine’s “audience communication” technologies, as Google Answers. Google Videos and YouTube were also competitors to each other. They do not create a single product for a single purpose. They encapsulate it from every angle.
“A targets B. C targets B. It makes A and C connected”. If you do not see this, talk to a doctor.
Thanks for sharing such good information about Google’s author ranking, and I will hope you also share more about Google’s author ranking.
Thank you, Digital Kool!
Thanks Koray, What a great detailed article! Specially on a topic that never discussed elsewhere.
I have a question regarding the “author vectors” calculation section.
Now if two author vectors got clustered together because they are very near to one another although the two authors work on different websites.
what is the effect of that on the websites? Could one of them get clustered with the other “getting over his shoulder” if its a high-quality one?
or what other indications, would “getting two author vectors clustered together” have in terms of ranking?
I mean would the cl
Hey Nader,
Yes, if two different authors create similar vectors, they would be classified together in terms of relevance, and for certain level of expertise evaluation. Many thanks for your kind comments.
Thank you for sharing the valuable content. Does that mean AI-generated blog posts should not be used at all? because they can be recognized as written by not a real person?
As long as the website operator adds “real-human” touch to the content, AI can be used as a writing assistant. But if the AI contribution is more than the “human-effort”, then the the search engine can re-consider the authority contribution of the author. Thank you for your valuable input.
Thank you for sharing a very valuable article with a lot of useful information with the community.
Thank you for your kind comment, Canvas. It means a lot.
Hi Koray,
This is truly a great article! However, I do have a question.
It seems this article was written prior to Google announcing that they don’t care if you use AI content as long as the content is helpful to the user. In my mind, this means that Google understands that it’s a losing war chasing/penalizing AI content and like you said many times, search engines prioritize how “cheap” it is to do something.
With that being said, they are still faced with the problem of “information bloat” due to so many AI websites but from my understanding, one of the ways Google is combating AI content is through the use of information gain and lack thereof.
Also, I would assume that Google is comparing Content Vectors (Website Content) vs Their Content Vectors corpus in order to determine if the website/web page Content Vectors matches up to what’s in their database. Thus allowing them to determine “authenticity for a topic” irrespective of who wrote the article.
So my question to you is, while i’m sure Google does prioritize real authors, especially for YMYL niches, would authorship results be considered negligible at best? Would not having these things such as a real author stop a webpage from ranking top 5 despite having all other metrics like backlinks from seed sites (just as an example), brand recognition, etc..?