
Entity Identity resolution is the process of recognizing an entity with its type, attributes, and values. Entity-Idendity Resolution is distinct from named entity recognition, but it is a necessary step in the process. Entities are living things inside the Knowledge Bases with different attribute-value pairs, which means that their identity changes with other types of associations. The optimization and control of identity shifts and changes in knowledge bases based on document statistics is known as entity identity management. Document statistics represent the entity values and their definitions with certain types of linguistic statistics, such as statements, declarations, or dense, that are retrieved from content items. For example, a document that is mentioned 99 times from 46 different sources is resolved as a “horse, animal, living thing” if it is mentioned 5 times from 2 sources as a “brand name.” It means that the entities’ first identity comes from the document statistics, but it doesn’t mean that the search queries are not important. For example, a search query might have 990,000 search requests per year, and signal that the specific entity is a brand, while the same phrase might be used in 9 other queries, but they represent an animal with 450,000 search requests. In this case, even if the document statistics represent an animal for the same phrase, the knowledge base gives more weight to the other profile of the entity. But, in information retrieval systems, mostly the query search demand and document statistics share the same correlations because of traditional SEO practices. Thus, a search engine might expect document and query statistics to align with each other, even if they don’t. In this SEO Case Study, we examine how document and query statistics create search memory in search engines’ entity resolution algorithms, and how it affects the Brand SERP, and Knowledge Panel Management. The specific SEO case study is titled “A Feminist SEO Case Study” because Google refers to and mentions a famous and successful Turkish dentist as an “ex-wife” within the Knowledge Panel, despite the fact that she has many other attributes in her potential digital and real-life existence. The main issue was that the subject entity’s ex-husband was and still is a media-holding owner in Turkey. Furthermore, some important factors caused fake news distribution without even triggering queries, and these fake news stories that harmed the entity’s digital reputation came in a variety of formats and from important, authoritative sources. The Brand SERP, Knowledge Panel Management, Exact Match Domain SEO Case Studies, and Guides are all related to the Entity Identity Creation and Management SEO Case Study. The conceptual definitions to explain the entity identity resolution and management for Knowledge Graph and Base control with document statistics are given at the end of the case study.
Background of the SEO Case Study, From an Ex-wife to a Dentist
Emek Külür is a successful and famous dentist and a medical expert in Turkey, the USA, and Europe with more than 30,000 patients on record. Emek Külür treated more than 30,000 people for better mouth and tooth health. She performed and published research on child growth, health, and habits, such as tooth brushing, to educate mothers and fathers. Mrs. Emek studied at the New York University Dentistry Faculty and worked together with Dr. Denis Tornow, and Dr. Norman Cranin at Brookdale Hospital. She returned to Turkey and established two separate dentistry and smile aesthetic clinics in two separate hospitals, Kadiköy Şifa Hospital and Memoeiral Hospital. She is a mother and educates her daughter to be a dentist. She has found her own company with the name of Smile Institute in Turkey. She is also a sculptor who loves art, and she designs her patients’ teeth while also creating implants.
In other words, the entity is a mother, an always-on learner, a doctor, a businesswoman, a sculptor, and many other things. But, imagine that Google defines this entity as only the “ex-wife” of someone. And this ex-husband, who is a media holding owner, along with some other people, publishes a lot of articles, which we had to clean up and suppress. Basically, this is a case study to change the digital aspect and identity of an entity that is associated with certain types of queries.
The SEO Case Study has been written during my Semantic SEO Course creation process. Furthermore, many screenshots and videos that I took are not included in the SEO case study. For example, for the query “Emek Kulur Treatment Fee” query, I have seen pornographic and fake content on adult websites intended to harm Mrs. Emek. In this SEO Case Study, as a consultant and always-on SEO learner, you can see the prominence of communication. When I have these types of heartbreaking results, I didn’t reflect them on the client, I just suppress them with different types of content. Moreover, during the SEO Case Study, I had to deal with news websites that received 5,000,000 or more clicks per month as well as websites that received only 40,000 clicks per month.
Thus, you will see three aspects in the SEO Case Study.
- How ChatGPT like Diaoluge-based Generative AI Systems can perceive entities.
- Why ChatGTP-like systems make real experts more important than ever.
- Why ChatGPT-like systems are extremely repetitive and limited to document statistics.
- Why ChatGPT is an accelerator, but not a solution for most SEO tasks.
- How Query and Document statistics affect the perspective of entity identities.
- How to change an entity’s most important attributes and values for these entities to change its overall definition in Google’s Brain (Knowledge Vault).
The screenshots and videos are from different timelines of the SEO Case Study. However, due to the Semantic SEO Course preparation process, the first screenshots and videos are not added to the case study.
The specific SEO Case Study will be updated further with new and existing samples.
To understand the Entity Identity Creation and Management SEO Case Study, you should read and watch the following SEO Case Studies.
- Predicates and Triples
- Entity Attribute Value Models
- Exact Match Domain SEO Case Study
- Entity-oriented Search SEO Case Study
- Lexical Relations SEO Case Study
- Brand SERP Management
- Knowledge Panel Management
- Google Author Rank
- Expanding Topical Maps
“SEOs are extremely powerful. We decide who will click what and learn, decide, and believe which statement about whom. The management of knowledge and the illusion of choice are two sides of the philosophy of knowledge. And, that’s why I love SEO.”
- Koray Tuğberk GÜBÜR
The First Situation of the Entity Identity with Fake Magazine News, and Being an Ex-wife
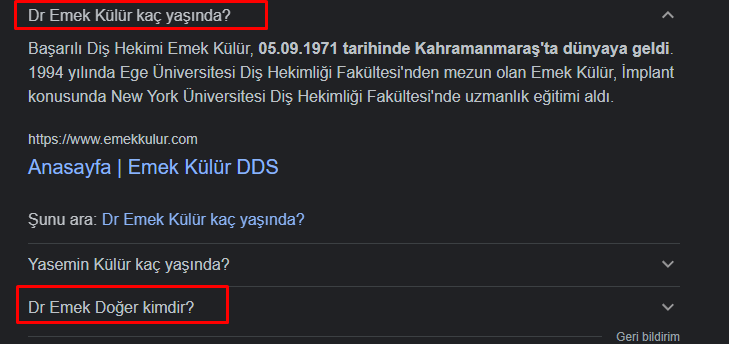
Entities of the type “person,” “place,” “organization,” “song,” and “movie” are shown in Google’s autocomplete with a picture or a subtitle that shows the most important thing about the entity. Below, you can see that Emek Külür’s entity is served as a magazine figure and ex-wife inside the auto-complete suggestions.

The other entities that are used inside the auto-complete suggestions have the attributes of “marriages”, “husband”, “divorce”, “lover”, “biography”, “ekşi”, “age”. All these attributes are heavily magazine-related, and none of them focus on the career of the person. The “ekşi” means a non-realistic forum in Turkey where anyone can write anything about anyone without any kind of legal obligations or limitations.
In the first few weeks, the “fake search demand” has been successfully created, and it is seen that it changes the order of the attributes. The “biography” attribute is a multi-layered contextual attribute because we can put “age”, or “business” inside it; thus, the first target inside the semantic network is the specific “biography” attribute, and the next step changes its connections to other attributes with document statistics. I call this the “Re-construction of Attributes” for the entity. “Fake search demand” has been used for the last 5 years to confuse Google, and the Google Chrome Developers team has a different team that is focused and assigned only to understand the fake traffic. Google always favors popularity, and if you fake popularity, their system is gamed. Thus, they are way more careful about these types of signals. That’s why these signals are used only for testing, to see the thresholds for search behaviors and query statistics, and to document statistical change that needs to affect the entity’s identity. I wouldn’t suggest you use fake search demand, or traffic without being a true expert. Another way of faking popularity is through “expertise.” Because the website publishers couldn’t fake the traffic, they faked the expertise with PageRank or AI Content, which brings us to the Google Author Rank research for understanding the real expertise. Thus, to play with the document statistics properly, the documents that signal different entity identities and contexts should have higher expertise. In other words, it is not just about how many documents define the entity; it is about who defines it, and with what kinds of trustworthiness and unique expertise.
Below, you can see how the entity identity has been changed slowly due to query statistical change.

The “biography” is merged with “kimdir” which means “who” question, and it is followed by the “business location” of Emek Külür, and “fiyat” which means “price”. Then, we have Instagram because Emek Külür’s Instagram account is associated with the business perspective because it is heavily used for business purposes. And, in the end, there is the “ex-wife” context, as well as the “ekşi,” which defines Emek Külür as an ex-wife. All this quick change signal means that the “ex-wife” context for the entity comes from an old “search memory,” which means that the document and query statistics are old, and the search engine is ready to change its own latest algorithmic decisions if there is new information. One more note is that the specific “ex-wife” entity image comes from a magazine source. In other words, the subtitle, and image source are aligned with the order of the auto-suggestions.
How does Semantic Distance help Autosuggestion to shape Entity Identity?
Semantic distance is the distance between two concepts or existing things with meaning. There are two main methods to measure the semantic distance between two concepts or real-world existing things. The first one is calculating the association and connection angles and their counts between two entities. The second one is counting the length of the connection length between two things with certain associations. In other words, if A is connected to B, B to C, and C to Z, it means that the semantic distance between Relevance calculation changes how to query semantics and document statistics are added together to make up the semantic distance calculation. Even if the semantic distance is 99 based on connection count, and length with a narrow association diversity, the documents’ PageRank, their vocabulary differences, and query metrics can change it. A Holistic SEO has to understand the search engine engineer, the engineer’s data, and limitations to bending entity identities, or topical map creation for a specific entity. For example, a document that ranks for 99 queries, contains 2 entities that exist in these 99 search queries, and 7 different predicates and the specific document is similar to other 17 documents that rank 400 more diverse queries with 23 different predicates, but mostly only one of these entities is labeled with these predicates, as an agent. In this case, the relations and associations between these two entities will change, and 23 different predicates will be reflected on the other entity for finding certain relevance, and similarities. The boolean words such as “and, or” will be used together with these entities. The semantic distance between this 23 predicate and the second entity will be affected by the associated other entity’s distance to the targeted entity as well.
These associations and predicates are reflected directly in the SERP. For example, the predicates that are associated with a “dentist”, and the nouns that are related to “dentistry” are united with the “price” attribute and the auto-suggestion. The “being”, and “having” predicates are united with the biographical attributes such as “age”, “husband”, “daughter”, “occupation”, “successes”, “ business”, “artwork”, and more. Affecting the document statistics for nouns, predicates, and their priority inside the documents shapes Google’s prioritization for attribute priority for certain entities.
The semantic distance between attributes and attribute-context pairs helps search engines rank the attributes based on how important they are for defining the entity. The count of angles and associations for semantic distance has two different angles. These are a count of associations and angles between two entities in terms of association types and association repetition. These kinds of associations demonstrate the context between two entities in the form of subject-object relationships with different predicates and semantic role labels. The number of repeated declarations for the specific object-subject contextual connections is represented by the repetitiveness of the connections and angles.
In the specific SEO Case Study, the importance of the attribute-context relationship has been manipulated by taking advantage of the lack of query variations. Since most of the queries involve only a single concept, which is the name of the entity but none of the other possible attributes, the search engine has to process and parse the query. Since search engines don’t have enough level of query variations, especially the specific document statistics, the macro contexts of the documents within the most important information retrieval zones become more important. For example, an Information Retrieval Zone is the point that expresses the relevance whether it is URL, title tag, headings, or ordinary textual paragraphs. The contextuality of the document comes through in the header and main introductory sections of the document that signal the direction of the next sections. The Context-Sensitive Person Search Invention of Google is a good example of the main entity resolution of the document, and the association between other entities. Most news articles start with a main entity and a specific predicate such as “President signed”, “Senator X appeal”, “Y Singer published”, etc. The second entity that is mentioned in the article gives the first association candidate, while the first predicate signals the association angle. The predicates and association candidates are correlated with each other, for example, the genders of association candidate entities and the possible predicates are correlated with certain context terms, and document layouts. Search engines cluster these associations based on their semantic distance from each other. If there are distinctively important different association clusters, they are curated together in the SERP. Especially, if there are no query variations or well-structured search queries in their query search session logs, it is a bigger issue for search engine engineers but an opportunity for the search engine optimization expert. Thus, the clustered contexts for entities are served based on their document and query statistics. To make a specific context cluster stronger, the association angles and kinds should be increased and made denser while the definitions and information amount are more precise with shorter connections.
In short, there are two types of SEO mindsets. The one that modifies its document based on the ranking of its competitor, and the one that modifies what the search engine perceives and forces its competitor to be similar to its own document.
- To affect the results on the SERP, many SEOs try to imitate the first ranking page.
- To rank on search engines, an SEO should understand what the search engine understands from the canonical query, and change the query’s meaning, rather than changing its own document cluster.
The concept of semantic distance is heavily processed by search engine designers and inventors because it affects the query path, and search route. The search route represents the searchers’ behaviors, selections, and queries based on these behaviors. As a result, the semantic distance should be contained within a relevance distance that adjusts context relevance. If two attributes or two entities are too distant from each other, they won’t be clustered together, and the document’s context will be diluted. If they are too similar, the specific query suggestions won’t be suggested; a canonical and representative query will be chosen for that. Thus, the documents that are used to affect the semantic distance should use a proper semantic distance understanding.
The Context-based Person Search is a good example of how the main entity, connected entity, connection context, and document clustering for them are performed by semantic search engines.
What are the Tiers of Entity Identities?
There are different types of entity identities that are used to define an entity. Every tier of the identity affects a different context for the specific entity. A search query such as “Who is Emek Külür” can be answered in multiple other ways such as “Emek Külür is a mother”, “Emek Külür is a human”, “Emek Külür is a female”, “Emek Külür is a businesswoman”, “Emek Külür is a businesswoman”, “Emek Külür is a dentist”, “Emek Külür is an artist”, “Emek Külür is an Author”. And, technically, any kind of noun that appears after the “isA” is actually an occupation, condition, or state. These nouns represent the types of the entity, and they are attributes for different angles. But, which one of these angles best defines the entity? It depends on the search query owner. In contrast, the search engine must take the average of the users. A search engine can cluster three things, users, documents, and queries. The clustered users’ query context and the served entity results’ context should match each other or should be relevant to each other. Thus, there are different tiers for an entity’s identity that search engines serve for different priorities, audiences, or angles. Thus, the first purpose of this specific SEO Case Study is to change the first tier of the entity identity from an “ex-wife” to a “dentist”. But, to come to the “dentist” tier as the primary identity, there were some other pauses such as “author”, or “journalist”. Adding new contexts and new tiers of identities to an entity helps a search engine re-evaluate the specific entity further. If the entity-related news’ density and velocity are high, the SEO needs to put in the same amount of density to affect the document statistics and query interpretation of the search engines.
What is Corroboration of Web Answers for Entity Identity Tiers?
Corroboration of Web Answers for Entity Identity Tiers involves corroborating different web answers from a web graph to find a mutual ground between different factual declarations with numeric values, or verbal qualifications. For example, for the definition of an alchemy formula, the sources that claim that the alchemy formula has over 7 pH level, and the sources that declare below 7 pH level are in a conflict. The search engines have to qualify, and evaluate the web sources for corroborating the answers and find a groundedness for factual questions. The Knowledge-based Trust and Corroboration of Web Answers are two different researches for Information Retrieval and Extraction systems to organize and evaluate the information sources on the web. The corroboration of web answers completes the knowledge based trust in terms of evaluating the trustworthiness of a source, and the centrality of a web source for factual information about an entity. The specific example for corroboration of web answers involve an alchemy formula and its pH level. If there are 90 web sources that mention the specific alchemy formula, and only 37 of them involve something related to pH level, the search engine has to filter the sources based on their attribute involvement. 37 different web sources for pH level might give 37 different pH level suggestions. In these types of situations, search engines can use their own Knowledge Bases that are fed with Data Commons, Freebase, or manual Knowledge Base improvements, or they can create a truth range with various corners. The truth ranges have maximum and minimum values for numeric value corroborations. And, if there is no consensus for a specific entity-attribute-value (E-A-V) data structure, the search engine can boost the rankings of a web source that states “pH level of X changes between Y and Z according to T, P, V resources”, in other words, hubs can outrank individual authorities as Andrei Broder who is the author of Taxonomy of Search mentioned. The truth range creation method, using non-open web resources, and web source filtration are three different methodologies for corroboration of web answers.
The entity identity tiers represent the different layers of definitions for the specific entity, and the most associated attribute has the highest centrality and priority for defining the entity. Thus, corroboration of web answers helps a search engine define which attribute, which value, and which association groups are most important, in what other candidate attribute-value pairs. For example, the Emek Külür is a dentist, but there are other types of dentistry, whether it is cosmetic dentistry, or restorative dentistry. Or, she is a mother, but mother of her own daughter, or an old stepmother for another person. She is a businesswoman but is a founder of Smile Institute or a founder of different clinics in prestigious hospitals. And, she is an ex-wife and a widow, a journalist, author, podcast show owner, a sculptor, artist, poet, and many other attributes, and values that are possible to use to define her. As in the Entity Identity Tiers, some of these attributes and values are more important than others for “who” questions, while some others are more important for “how” questions. For example, the “Does Emek Kulur know trading” question has an annotation for “stocks” because, she has the attribute of “businesswoman”, but the same predicate might be matched with another object if Identity Tiers would miss “businesswoman” but involves “sports coach” because “trade” annotates “trading players under contract” for sports context. Corroboration of web answers helps to understand which attribute has which value candidates from what range, and for what types of questions, answers, predicates, and nouns.
Why are the Embarrassment Factor and Safe Answers Important for the Corroboration of Web Answers?
Search Engines and Information Retrieval Systems have an embarrassment factor, which explains how a search engine company would be shamed based on bad, inaccurate, slow, and non-responsive answers without proper relevance and logic. Thus, corroboration of web answers are needed to create a consensus. Consensus or groundedness helps search engine systems give Safe Answers. Safe Answers are not necessarily accurate answers necessarily, they are the answers that do not make any side uncomfortable, and create a collaboration between the question and answer owners. For example, the question “Where was Barack Obama born” might seem like an innocent question, but if the document mentions “Birth Certificate”, it will be about the “politician” attribute and the priority identity tier of the person entity, which is connected to a highly political debate. The question “Is Donald Trump an idiot?” might be seen as offensive, but search engines need to answer the questions, and the answer to the question might put a search engine official into court to defend their algorithms.

Thus, political debates are under the category of “inappropriate context.” The “Hilary Clinton Emails” have an entity and an attribute that annotates the communication prints of a politician who is tied to a political crisis. Google directly removes the “email” attribute from auto-suggestions and documents that mention the specific context from rankings for the entity’s name. Because of this, the search engines need to use Safe Answers, Safe Contexts, and Consensus to satisfy more users.

While a political leader blames a search engine and sues it for not being transparent, objective, and nation-friendly, a search engine engineer can’t continue to work on the datasets that the company has. To use these contexts for Entity Identity Creation and Management, a Semantic SEO should understand the concept of safe answers. If the specific consensus is not created and the context is not safe either, the number of declarations, statements, and answers to be corroborated from different sources will increase. In the situation of Emek Külür, the opposition tried to create an identity for “pornography” by using the “price” and “service” types of attributes. Since these contexts are not safe, and it is easy to use Google, these documents are easily suppressed by the other documents’ statistical contexts and information. To use attributes such as “beautiful”, or “attractive,” the specific “pornography context” had to be removed. Because, contextual concepts such as “magazine”, “love”, “lover”, “scandal”, “new relationship revealed” etc., are easier to connect to adult contexts. To connect these specific “spouse” related predicates, and nouns, the “artist”, “art”, “author”, “podcast”, and the first husband, “Behzat Külür” who is the father of daughter Yasemin Külür are used.
Why is the Nature of Meaning relevant to Google’s Understanding of the Definition of Things?
The meaning of nature involves semantics, semiotics, philosophy of language, metaphysics, and metasemantics. MeaningThe meaning of nature explains what a thing means from different angles. For example, psychological theories, truth conditions, measurement, computation, and logical theories define things with different meanings. Truth changes based on the theory that is chosen for the meaning of nature. For example, Correspondence Theory says that the correlatives of a thing and its expression should match each other. If an expressed idea has a representation in the universe, it should be true. But, while things expressed might not have a true side for this century, they might have one in the next one. As a result, correspondence theory may not be the best approach for a search engine like Google to understand the truth. Google-like search engines (semantic and hybrid search engines) need to define the truth and define things based on the searchers’ perspective to satisfy the users. The definitions of nature theories are below.
- Correspondence theory: Correspondence theory is a philosophical concept that states that truth is defined by how accurately an idea or statement corresponds to reality. This means that in order for something to be considered true, it must accurately represent the facts and realities of the world around us. Correspondence theory has been used throughout history as a way of determining what constitutes knowledge and understanding about our universe.
- Coherence theory: Coherence theory can provide an alternative perspective on determining truth and accuracy when compared to Correspondence Theory. Coherence theorists suggest that instead of relying solely on facts from the outside world for verification, one should also consider how well different statements fit together logically within a given system or framework of thought; this means looking at how consistent ideas are across different domains rather than just focusing on their individual correspondence with external realities alone.
- Constructivist theory: Constructivism is a way of thinking about how people learn that stresses how important a person’s experiences and knowledge are to how they learn new things. This theory was first made by Jean Piaget in the 1920s. Since then, many other educational theorists have changed and added to it. Constructivist theories are based on the idea that people actively construct their own meaning from their experiences, rather than passively receiving information from external sources such as textbooks or lectures.
- Consensus theory: Consensus theory is a theoretical framework that proposes that social order and stability can be achieved through the collective agreement of individuals within a society. This theory suggests that when people come together to form an understanding or agreement, it creates harmony among them, allowing for peaceful coexistence. While this concept may seem idealistic in nature, there are some valid arguments for its use in the study of sociology and political science.
- Pragmatic theory: Pragmatic theory of truth is a philosophical concept that states that the truth of any statement can be determined by its practical consequences. This means that if something has beneficial or desirable results, then it is considered to be true. The pragmatic theory was first proposed by Charles Sanders Peirce in the late 19th century and has since been developed further by other philosophers such as William James and John Dewey. The main idea behind pragmatic theories of truth is that statements should not just be judged on their logical validity but also on their practical effects.
- Logical Positivism states that truth should be verified. Logical positivism (logical empiricism, neo-positivism) involves the verification principle. It originated from Ludwig Wittgenstein to turn philosophy into scientific philosophy which means if something is not verified, it is not part of the truth, and it doesn’t carry value even if it is philosophically complex and well-structured.
The consensus theory is the most important and useful way for search engines to figure out what the truth is. Because, consensus theory is the output of all the other nature of meaning theories such as pragmatic theory, constructivist theory, or coherence theory. Search engines like Google use KeALM-like language models to verify a fact from a web source based on their own knowledge bases. And, Knowledge-based Trust is used to understand trustworthy sources for defining an entity. Thus, if a fact is accepted pragmatically and proven by multiple other signifiers while being observed and experienced by big amount of people, it will be a consensus. The opposite of consensus theory is the “illusion of choice”. For example, a search engine optimization expert can create two million unique documents to define a non-existing animal, and a search engine can assume that it is a real-world entity that creates an illusion with digital content network creation. The same goes with affiliate marketing, the highest revenue creating a product is linked most inside the best product listicles which end up with that product becoming more important. Thus, it is not clear whether the consensus comes from searchers or publishers. A searcher searches for truth, then the searcher gets a factoid from a web source, and the factoid becomes a consensus, then another publisher tells the same to rank for the specific question group. This illusion of choice and consensus on truth created the concept of Information Quality.
Why are factoids important for Entity Identity Creation and Management?
A factoid is important for entity identity creation and management because a factoid is the unification of an opinion and a truth statement without a strong verification. Thus, search engines have to qualify and use factoids by auditing them to define the entities. Giving a certain amount of factoids from multiple authoritative sources create a consensus about a truth-related question. The answer-seeking queries for certain entities and attributes help search engines locate the context of the query and the topic of the entity so that the specific factoids are presented to satisfy the need of the user.
To understand the importance of a factoid for Knowledge-base Construction around entity-related questions, the definition of a factoid should be understood in the context of SEO. A factoid is a statement or piece of information that appears to be true, but has not been verified and may even be false. A factoid can also refer to an otherwise unremarkable item of trivia that is presented as if it were factual. A factoid can also be a piece of trivia that is not very interesting but is told as if it were true. Factoids are often reported in the media without any verification, leading them to become accepted as truth by the public over time. This makes distinguishing between what is a fact and what isn’t increasingly difficult for people who rely on news sources for their knowledge base.
The main difference between facts and factoids lies in how they are verified; facts have evidence that supports their validity, while there may be no proof behind a purported ‘factoid’ at all, making it impossible to verify its accuracy or authenticity beyond doubt. Facts come from reliable sources such as scientific studies, while most ‘factoids’ originate from unreliable ones like gossip columns or blogs with no real authority behind them—though this does depend on context too, something might appear on an authoritative blog one day only for someone else later down the line to repurpose it into something entirely different without citing where they got it from originally!
The factoids and opinion-based articles for ranking algorithms are processed by Koray Tugberk GUBUR in News SEO Conference in 2022. Reach out to specific presentations to understand how search engines determine facts and factoids for ranking purposes from the image below.

How to Affect Document Statistics with Legal Ways?
Affecting Document Statistics in legal ways involves changing the existing and ranking documents on the search engine result pages by using legal execution to remove harmful results. To remove the harmful results, and unwanted documents that amplify different entities identity tiers and attribute-value sets, the SEO should understand the laws, and find opportunities to use them in court.
When beginning the specific entity identity creation and management project, legal methods are used to remove some web pages. Non-SEO methods affect SEO as long as they work to affect the opposition. For example, in Casino Industry in Turkey, it is normal to find the identity of the opposition, and sue them for breaking the law. I know people who are still imprisoned or on the run in Central Asia, Georgia, or China-like countries. Thus, Holistic SEO is not just about using every vertical of SEO, it is about using every possibility of effort for improving SEO results and performance, whether these possibilities are online, or offline. It is a full-fledged SEO campaign that covers every possible angle.
Since Emek Külür is a businesswoman, and a mother, the results below are removed by using the law. There are more samples that were removed by legal force that I hired, but to explain the context of these results, I will just translate their URLs in parentheses.
- https://www.posta.com.tr/magazin/galeri-emek-kulur-yemin-ederim-sevgili-degiliz-2326575 (I swear we are not lovers.)
- https://www.magazinsesi.com/nisantasi-nda-surpriz-ask-levent-uysal-ile-emek-kulur-ask-yasiyor/139/ (Surprise love with Levent Uy… and Emek Kulur)
- https://emlakkulisi.com/sosyetik-disci-emek-kulur-aidat-borcu-nedeniyle-icralik-oldu/669889 (Magazine focused Dentist Emek didn’t pay her debt)
All these results are removed because they were harming the commercial activities of the brands that belong to Businesswoman Emek Külür, and her dignity as a mother and human.
How to Affect Document Statistics with Search Engine Communication?
Affecting document statistics with search engine communication involves using methodologies for removing certain types of documents from the served index while adding new documents to suppress the rankings and prominence of other documents. To affect the document statistics through direct communication with the search engine, forms and report feedback are used, while document creation and publication are used for indirect communication with the search engine. The reports and feedback forms for certain documents to remove them have different variations and reasons for use, such as personal information, credit card information, misinformation, trademark use, and more.
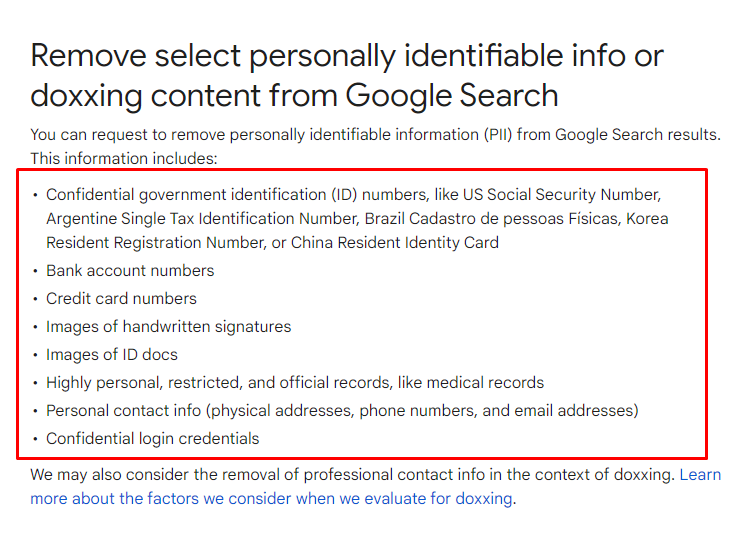
The form from Google below demonstrates a “personal information removal request” with direct communication. Google suggests contacting the website owner, but most of the time it doesn’t work. Thus, the system below provides a multiple-choice form with different optional flows according to the choices.

Below, the “Doxxing” related content removal requests are involved. The images of handwritten signatures, bank account numbers, home or office addresses, email addresses, login credentials, bank account numbers are some of the sections to use for content removal requests by google. Google defines these information as “Personally Identifiable Information”.
Google uses the “More about this page” panels with the “Remove Result” button to help search engine users who want to state an opinion or request an existing SERP snippet and URL.

For example, the result example below demonstrates a magazine news removal request by Google. The news says “Emek külür is unhappy in work-life, and also in business life” as a misinformation. And, “Personally Identifiable Information”, or “any kind of outdated, and illegal” information can be used for requesting removal.

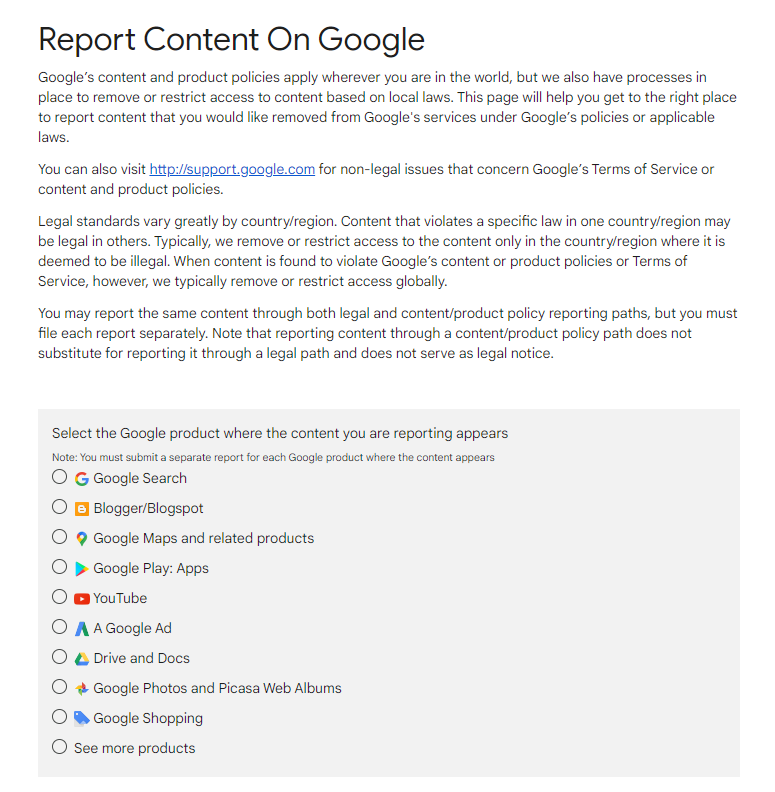
Google has a documentation for affecting the document statistics with direct communication called “Report Content on Google”. From YouTube, to Blogger, Google Drive, Google Shopping and Googl Search, requesting a removal based on country and region is possible. According to the country and region, since the law-related aspects change, the decisions of the Google can change for contnet removal request about the entity identity.
Google gives further information about processing content removal requests based on the legal policies that involve privacy guidelines and community guidelines.

Defamation is one of the most common content removal request reasons, and it is the most preferable since it is easier to prove and doesn’t require Personally Identifiable Information (PII) obligations for filing a removal request. Thus, choosing more gray areas, and blurred justifications with multiple arguments for content removal requests from multiple Google Accounts, while complaining about the specific web source based on multiple other entities is useful to gain further trust for the requests for content removal.

An example of a content removal request for Brand SERP Optimization and Entity Identity Creation and Management is above. Google places “reCAPTCHA” directly because there is a lot of automation for suppressing the dataset with the flow of content removal requests.
YouTube has two different content removal systems and forms for the users and video searchers. One is on the search results page, the other one is inside the YouTube video page.
The content removal and complaining form inside the YouTube Seasrch Result page for Entity Identity Management are used to complain about thumnbais, and video titles rather than the video content which shows that even the autoplay via mouse hover-over on the video doesn’t relate to the actual content of the video.
The YouTube Video Page complaint form has more detailed options to complain about, and the good part is that it has a minutes and seconds locator for the respective complaint. Complaints for harassment, misrepresentation, sexual abuse, and child abuse all have justifications in the video-based complaint form.
The report image or the title form of the YouTube search engine is below.
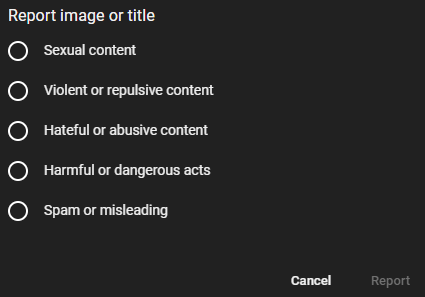
The Report Video form of the YouTube search engine is below.

After choosing the specific type of complaint reason such as captions, promoting terrorism, or spam and misleading, the video-time locator is used to locate the spam reason.

Google and YouTube are able to locate the words, contexts, and video segments based on the anchor segments inside the videos. In other words, “In Video Search” is a real search path for Google and YouTube. The “In Video Search” helps users locate the most relevant section of the video for their queries and needs. Google and YouTube are able to generate text from the videos, and they mark words with timestamps to locate the most relevant section of the video. But, in-video search works with Temporal Local Actions, Video Frame Chanes, Frame-Object detection along with Word-Context-Timestamp matching. Two examples of research on the specific topic are “VideoBert: A Joint Model for Video and Language Representation Learning” by Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmand “Visual Semantic Labeling for Video Understanding by Arka Sandhu, Tanmay Gupta, Mark Yatskar, Ram Nevatia, and Aniruddha Kembhavi. Both of the studies explain how videos can be resolved and interpreted for entity recognition, context dissolution, and relevance understanding. Google Search Off The Record Podcast’s “Cats, muffins and more: Videos in Search” episode explained video indexing, and Google stated that there are more natural language processing and video processing technological improvements needed for understanding video search behaviors completely. The complaint forms for entity-identity management and creation on YouTube are related to video search algorithms, video understanding, and In Video Search technology. Because there are three thresholds to satisfy in order to persuade YouTube and Google that specific videos are spammy.
The quantity Threshold for Content Removal Requests involves the number of users, and the complaint count from these users for removing the specific content item from YouTube. YouTube is able to resolve and process complaints and content removal requests, whether the users are authentic or not. The view count, comments, likes, or watch time metrics from the fake user accounts are removed from YouTube data as a result of the fake content removal requests and complaints.
The Velocity Threshold for Content Removal Requests involves the frequency and intensity of the complaints over a certain amount of time. Exceeding the complaint quantity threshold in one year, and in one day does not reflect the same emergency for removing the specific video.
Relevance Justification for Content Removal The request contains content that must be removed. Whether the specific content removal request is automated, shallow, has deep information with proper human effort, or is just for spamming the complaint report is audited.
Google’s experience with content removal requests is coming since 2009 when Scientology complained about a video and a blog about themselves, Google has taken over 2,000 complaints and content removal requests a day. But, still, in terms of freedom of speech, Google kept the documents and suggested that both sides comply with the law. The explanation from Garry Illyes, a Google spokesperson for content removal requests and complying with the law section validates this.

Google’s blog post “When (and why) we remove content from Google search results” explains why they can’t remove any content directly but need automated, semi-automated, and fully manual explanations, justifications, and removal processes. In terms of the Identity Creation and Management SEO Case Study, complaint forms and content removal processes can be used to change document statistics and entity search results. In the Emek Külür Entity Identity Creation SEO Campaign, forms from Google, and YouTube are used.
- Removing some of the harmful videos from YouTube search results directly, and from Google indirectly.
- Removing Video Carosuel due to heavily complained video content from Google SERP.
- Suppressing the Video Results with Landing Pages via news sources and new Podcasts.
- Balancing the Video and Audio results’ statistics with the created Podcast for Emek Külür to show content richness in terms of content format for the entity identity.
- Using Emek Külür’s new images as the video thumbnails, while also filling the complaints about the existing magazine videos’ thumbnails. This helped us remove videos thumbnails from image searches.
The first situation of the Emek Külür related search results with the heavy video carousel existinte is below.

The specific video carousel creates an issue for the reputation of the digital entity owner because these results directly aim to harm the credibility of the person. The thumbnail images, titles, and content of those videos are suppressed in rankings and in the Universal Search Results which are identified with the word “All” in Google SERP.

The SERP instance above shows that the video carousel is removed and it is not served more than 5% of the time. Even if it is served, it shows mostly the scientific, and business-related points and angles of the entity. The marked section in the image reflects that only YouTube result is coming from the Podcast Series that we have done together with Emek Külür. And, this video has a long 5,000 characters of description for explaining who is Emek Külür, which is aligned with the video title.
The title of the video “Who is Emek Külür, Education and Personal Life” which signals our angle for the video, and the identity of the entity. The other removed two videos focus on “legal problems of Emek Külür”, and “Magazine love life of Emek Külür” which are suppressed in document statistics, and search behaviors. The two different entity identities that are created for Emek Külür are given below.

One of these identities is completely new, the other one reflects “creation”, and the other one is manipulated by me and annotates “management”. Before continuing further, look at the image below one more time.

The entity identity that I have created focuses on scientific and business attributes, with the primary “dentist” identity, and second one that I have manipulated uses the “Dentist” sub-title, but it has historical data from magazine context, and the previous sub-title was “ex-wife”. At the first section, we explained how the document statistic affects the Google auto-suggestions. Google removed some of the magazine related auto-suggestions, and used the dentistry and business related attributes in auto-completes after changing the search behaviors. And, similarly, the overall historical data, and the previous sub-title’s characteristics which reflect the ex-wife primary identity is merged with dentistry. Thus, it is connected to the phrase “Magazine-related Dentist” which is used inside the titles of these videos. Phrased-based Indexing, and Entity-Phrase Associations are related two different Google designs.
Patents.
Thus, the unification of these two video groups, one mentions “Dr” and “Doctor”, and they are scientific, other two uses the words “Magazine Dentist” are curated and ranked together. The current situation of the video search results with 2,240 videos is below.

The 80% of the video results are about scientific identity of the Emek Külür, and %20 of them are the magazine-like videos. The magazine like videos rank at the 1st and 9th places because most of scientific attribute videos and content are coming from the same source which is the official YouTube Channel of the Emek Külür which is a signal for search engine result diversification need. In other words, video content diversity and video source diversity are needed to satisfy the threshold of search engines for ranking purposes.
- To help Emek Külür’s official YouTube Channel, 2 past interviews and webinars and 7 different podcast videos have been uploaded.
- Multiple other fake YouTube Accounts are created to curate content from other YouTube Channels related to Dentistry.
- The YouTube Video curation and syndication linked to and mentioned Emek Külür’s official YouTube Channel.
- The YouTube Handlers are used to link the accounts along with the description area and comment area links.
- The duplicated videos used different thumbnails and video descriptions, along with the YouTube timestamps.
These methodologies are used because of the lack of new video content. In other words, since we can’t create new video content frequently, we had to distribute the old content with new labels, and contexts. These contexts are created by modifying the meta-data of the video and curating it with other videos from different channels. For example, “The Top 10 Dentists of Turkey”, “Dentistry Turkey”, “Emek Külür Dentist” types of different YouTube Channels are created for the curation of YouTube videos that involve Emek Külür and other dentists. These publications are not done for ranking purposes, but for affecting the document statistics, and signalling the prominence of canonical videos in certain contexts so that search engine can cluster these videos, and chose the centroids as important. Document cluster gets bigger, centroid gets more prominence from ranking algorithms for different contexts.

The section above is for explaining the prominence of Human Effort for Search Engine Optimziation, it comes from Google Quality Rater Guidelines, page 21. It explains that any kind of curation or content creation without effort is not quality which means that the documents that are created on YouTube from duplicate videos are not appropriate for ranking, but good instruments for signalling the prominence of original content further. The Document Clustering methodologies for search engines are important for Entity Identity Creation and Management SEO Campaigns as in semantic SEO projects for manipulating the representation of information with authoritative sources. The SEO Case Study below explains how two different sources give the same reactions to the same Google algorithms, and how one of them suppresses the rankings of another as a representative.
How do Content Removal Requests Affect Google’s Judgement for Documents?
Content removal requests are similar to Google Search Console Content Removal requests with one difference, one comes from the website publisher, and another one comes from an external user. Google’s algorithmic behaviors for crawling, indexing, ranking, or evaluating of a content item for topicality and quality don’t change based on the content removal request’s source as long as the request is approved. The main difference comes from the source of the request which affects the process of the request. While GSC content removal requests are approved directly, the approval of the external content removal requests take a longer time with further justification and repeated requests. The same goes for content removal requests on YouTube and Google SERP. In this context, Content Removal Requests are signals for Embrassment Factors and Inaccuracy or Misleading content for Google search engines, thus a certain amount of documents might be removed from the served index of Google, or they can be demoted regularly and gradually.

Entity Identity Creation and Management SEO campaigns should leverage the content removal requests by blurring multiple reasons and justifications from multiple angles to increase the change of removal, or demotion from search engine result pages.

In the context of entity identity creation and management, the Content Removal Tool for Outdated Content Guidelines states that the specific tool shouldn’t be used for owned websites, Google suggests using the GSC Content Removal Tool directly, and for legal and security reasons, Content Removal Policies should be followed.
The content removal guides for legal reasons redirect users to Business Information, Google Opt-out, and Knowledge Panel Management for entity identity reflection on the SERP.

The content removal requests cause Google to crawl fewer pages, demote the rankings, and find safer answers and contexts for the specific entity and attribute pairs. Examining Google’s behaviors on URLs removed from SERP via the GSC Content Removal Tool allows you to see how the crawl rate changes, how Google uses the content for internal link exploration, and more.
More than 4,000 content removal requests from various accounts have been used in the Emek Külür Project to demote certain types of aspects and content in order to give a higher chance to dentistry and non-love-related attributes.
How do Content Removal Requests Affect Google’s Judgement for Web Sources?
A web source that is affected by misinformation and sexual harassment-type content removal requests can’t be considered a trustworthy source anymore. As a black hat methodology, multiple websites that mention a specific web source as spammy, or non-trustworthy in their own Disavow File can cause the specific website to be examined as a spammy source. Similarly, a web source that is complained repeatedly and justified way can experience ranking demotion. Certain aspects of harmful content websites and their signals are processed in Google Quality Rater guidelines and in certain Google designs such as “Setting default security features for use with web applications and extensions”.

Google Safety Center is a similar product of Google to help users and web developers to keep web safe not just from web security threats but personal information leak.

For example, Google Safety Center has a phishing report page that enables users to request certain types of web pages to be removed from the SERP.

All these types of requests can help SEOs to fight against spammy, misleading, and personal information-distributing websites. In my 40 Deep SEO Insights Twitter Thread, I already explained that Google labels websites sometimes in the wrong way due to certain signals. A classifier always has a flaw to exploit. Thus, to communicate with search engines efficiently, the SEO needs to give the same meaning, message, and context from multiple sources, layers in different formats with consistency so that a high level of confidence score can be acquired.

For example, an entity that is mentioned as an ex-wife, and a dentist in two different groups of document clusters might be seen from the point of view of Information Quality which involves prominence, interestingness, and safety of information. And, if one of the clusters has 2,000 content removal requests, while some of these results are already 404 due to legal processes while another cluster has higher quality web sources with fresher dates, the search engine’s confidence score can be increasingly easier to manipulate in a certain direction or manipulation. And, it is an absolute fact that search engine manipulation is part of search engine optimization. Manipulation of search engines does not need to be bad, it is helpful to make search engines process faster in a quality direction.
How do Content Removal Requests Affect Google’s Judgment of Entity Identities?
Content removal requests affect Google’s Judgement of Entity Identities in terms of entity-phrase relevance and association and entity-context, entity-attribute pairs. Changed document statistics due to entity identity creation and management projects while creating new documents and removing some others help the search engine be more confident about certain angles and qualifications for certain entities.
In other words, “Apple” is a fruit and a company, but all the documents about “Apple the Company” are removed from the web in one second, Google would need to change entity-phrase associations quickly to stay updated.

The figure from “WO2014150214 – QUESTIONS ANSWERING TO POPULATE KNOWLEDGE BASE” of Google demonstrates the importance of document statistics for entity perception. Entity identity changes if the connections and associations change, which means the example graphic above from Google would change, and be verbalized differently.
How do Content Removal Requests Affect Google’s judgment for Consensus about Entities?
Consensus for search engines is part of Information Quality understanding which means if an item of information is not in the consensus, it is not quality, safe, or accurate. Consensus affects entity perception, resolution, recognition, and association with search engines.
Entity Homes and Topical Maps
Entity Home is a concept that is found by Jason Barnard as Brand SERP, and Knowledge Panel Management. The Entity Home is a specific web page from which the search engines learn the entity identity, attributes, and values. These web pages are the centroids within the web page clusters that define the related phrases, attributes within phrases, queries that are connected to phrases, other entities that are associated with the entity, and value types such as date, amount, age, weight, height, artwork, opinion, stance, and more. The entity home creation process is the process of creating an Information Point within the web for defining the entity. Information Point is a connected concept to Information Retrieval. Prabhakar Raghavan (Vice President for Search at Google) defines the Information Zone concept as a zone on the web page to understand the relevance, while Information Point is a zone to extract information rather than understand the relevance. The Information Point is connected to Information Extraction and found by Koray Tugberk GUBUR, founder of Holistic SEO & Digital. The entity Home concept is helpful to understand the importance of Entity Definitions. But, the Corroboration of Web Answers is related to Entity Homes, because what happens if there are 3 different entity homes that conflict with each other?
- Information Zone: A concept from Information Retrieval for understanding the importance of a zone of a web document for calculating the relevance. Web page segmenting, term weight calculation, typography and layout inferring, text processing, and content analytics are related to Information Zone.
- Information Point: A concept from Information Extraction which is a sub-process of Information Retrieval for finding responsive information to specific questions, or question-like queries.
- Entity Home: A web document that defines an entity comprehensively and authoritatively, a source of factual information for grasping the definitions, and attributions of the entity.
The Consensus Theory for Nature of Meaning, and Corroboration of Web Answers based on authority, centrality, expertise, and experience is related to conflicting multiple-entity homes. And, to have better Brand SERP control, an SEO Campaign might change the entity home for defining an entity, or the source. Creating multiple entity homes for defining an entity is a helpful process for finding different attributes, and contexts in a controllable way for Entity Identity Creation and Management.
In Emek Külür’s SEO Campaign for defining her digital entity, three different official websites are created.
- Emekkulur.com
- Emekkulur.net
- Emekkulur.org
The Entity Identity Creation and Identity Management SEO Case Study is relevant to the Exact Matching Domain SEO Case Study because it relies on EMDs for entity home creation. All these Entity Homes are registered to Google Knowledge Graph via the Knowledge Panel Registration system of Google with a real-world ID picture and selfie. And, in Knowledge Panel Management System, the Celebrities were allowed to post text and images for managing their SERP. The Entity Creation and Management SEO Case Study leveraged the Google Posts at the beginnig for enlarging the surface of the web for Emek Külür so that the document statistics can change further.
The Google Cameo has been used in the Entity Identity Creation and Management project, but Google shut down the Cameo during the project, because Google realized that people care about third-party independent sources for defining the celebrity entities. In this case, it is important to notice that the need of multiple sources that corroborate with each other for defining entities is important for defining a well-established fact, and entity homes can’t be the opposite of the corroborated answers.

What are the Examples of Entity Homes and Entity Identities on SERP?
The examples of entity homes and entity identities involve different types of entity home documents to define entities and affect their served results on the web. The beginning of the specific SEO Case Study has the original and the raw result below.

- The theme of “ex-wife” is directly in the sub-title of the entity.
- The wedding, and ex-husband theme are in the images.
- The “people also search for” section shows magazine related entities directly which are related to only “love” relationships.
- The knowledge panel is not claimed.
- There is a magazine definition for the entity from a magazine newspaper.
- The only attribute is “spouse”.
The project started to construct a new entity home while giving a new entity home to the existing entity.
Below, you can see there are two different entities with two differnet subtitles, one is “dentist”, the other one is “ex-wife” for the same person.

The ex-wife related entity’s identity has been changed as below.

“Yazar” means “Author”, since the Emek Külür is an author in nespapers for children health and dental health, Koray Tugberk GUBUR used the “emekkulur.com” as the entity-home, and changed the sub-title as “Author” by re-defining the entity.
The important part here is that there are two different ways of changing the information inside the Knoweldge Panels.
- Affecting the Knowledge Panel attributes and sections indirectly.
- Affecting Knowledge Panel attributes and sections directly.
Direct management of Knowledge Panels in Google happens via “Claiming the Knowledge Panels.” To have the direct control, the entity should be verified on Google. Google has a document with the title of “Get verified on Google” with 6 steps.
The named entity verification on Google involves steps like having a Google Account, verifying the entity identity via Google Search Console that is connected to the entity home doument, selfies, IDs, social media accounts and access tot he social media accounts.

It is important to know that an entity identity owner can add users to help with Knowledge Panel Management. In other words, someone might transfer ownership of an entity identity, or add assistants to manage the same entity knowledge panel.
In this case, to have a direct control and suggestion communication with Google Systems and teams for knowledge panel creation and organization, the SEO should be in the added users for knowledge panel after claiming the knowledge panel process is completed.

For the ownership process, Google defines “entities” also as “topics”, and suggests using websites for proving the ownership.

Verification with “third-party platforms” such as Twitter and Facebook demonstrate the importance of social media feeds for defining the entities and how to take the advantage of follower base of the celebrities and other types of person entities on Google SERP.
Example of registered entity to Google for the Entity Koray Tugberk GUBUR on Google with “Consultant” subtitle is below. The important thing here is that the existence of the entity on different languages might change. And, attributes, values, contexts, priority of attributes for defining the entity might shift from a region and language to another. Thus, in the example below, the Turkish results for defining the entity is seen. And, the entity home, definition, and results change based on that.

The example below shows the results for English search of the specific entity.

The benefits of having a multi-language identity on Google consistently for SEO and Entity creation and management are listed below.
- Having an entity home in another language might be easier compared to the targeted language.
- The entity home from another language might affect the validity of another entity home from another language.
- An entity whose type is “vegan activist” can’t be a “meat chef” in another language, thus corroboration between other languages and regions is important.
- The document statistics might be changed easier for another language which affects the targeted language results indirectly or directly.
- Google gives translated results from the comprehensive and quality pages directly for other languages if there is not enough level of information on that language. The published Multi-lingual and regional SEO case study explains translated results, and how semantics are language-agnostic. It is helpful to understand multi-lingual and semantic SEO together for constructing a meaning-based search engine for satisfying meaningful search behaviors and needs.
- The entity-homes, and corroboration web pages for supporting the information on the entity-homes should exist on different languages for increasing the confidence of the search engine.
The Emek Külür already has connections and associations for the foreign language entities such as Newy York University or Brookdale Hospital, thus iti s ieaser to connect her to English language entities and results. Thus, multilingual news-papers are used to change the search engine’s perspective for other languages as well, including Turkish language results for the person-search.
The Named Entity Consolidation has two different meanings for Entity Identity Craetion and Management projects.
- Consolidation of a named entity between languages with different aspects.
- Consolidation of a named entity between two different entity registrations.
To understand the named entity consolidation, the concepts below are important.
- Named Entity Recognition is the process of recognition of the entity.
- Named Entity Resolution is the process of understanding which entity annotations signal the same entity.
- Named Entity Linking is the linking of the entity to the most important entity document, which is entity home.
- Named Entity Registering is the recognizing and registering a new entity that is not seen before. Registering a new named entity to the search engine systems is “Entity Creation” which is different from “Entity Identity Creation”.
The Named Entity, Emek Külür is consolidated between Turkish, and English, while conceptual consolidation happened between Author, Journalist, Dentist, Artist, Showrunner while excluding the ex-wife attribute.
An example of the direct entity knowledge panel control and change request is below.

The requested changes by the entity owner are not always accepted, and sometimes the results of the request might be completely different from the actual request. For example, requesting to add a Pinterest account to the Knowledge Panel of the Entity caused the addition of a YouTube Account while Pinterest is still not there. The duration of waiting for a change after making a Knowledge Panel Change request directly changes according to the entity’s prominence, region, and language. In the Emek Külür project, the duration of change requests for Knowledge Panel Management changes between 3 and 10 days. Google uses automated and non-automated systems for approving change requests, as in Google Posts on Google Business Profiles.

After using the “author” subtitle for the entity, the changes on the Knowledge Panel are visible above.
- The images with “wedding theme” have been removed.
- The ex-husband is removed.
- The spouse attribute is removed.
- Educational information such as “University” with “Ege University” value is added.
- The entity’s home has changed.
- Information on the entity home is changed.
- The “Author” subtitle is used.
The future process became a little more complicated. Because, it is easier to get an “Author” profile on Google, if you have a “book” that is published, even if it is inside Google Books. But, Emek Külür didn’t have one.
- A book for biography of Emek Külür is planned.
- The Podcast Series for Emek Külür is planned together with the book.
- The Podcast Series are completed.
- The Podcast Series for Emek Külür is used on Spotify, SoundCloud and other Corroboration Sources, and Podcast Series showed the prominence of the entity from different search verticals.
- The Podcast Series of Emek KÜLÜR is not turned into a book yet, but it will happen for improving the project further.
- The “Author” subtitle is turned into “Journalist”, because most of the artwork of the Emek Külür came from a newspaper.
- Google changed the entity’s identity to the Journalist, and it changed entire SERP Features directly.
- It is called “Dynamic Serving of Content” by Google.
- The sidebar on the SERP, or the “content type refinement” for entity search results include different aspects, and angles for the entity.
- After having the Journalist Subtitle, the “articles” of the Emek Külür are curated together, and served which helped for future steps to define the scientific approach for the entity.
- Thus, using different subtitles for a named entity is helpful to fasten the sub-processes of curation of information for serving purposes such as recognizing the articles, and connecting articles to the author with a certain authority.
- The connected articles are used for making the new entity homes more important and central for the professional profile.
- The served journalism material for Emek Külür’s articles are used during the Dentistry subtitle is active, but the author attribute was different.
- Planning these strategical steps require understanding the engineering of the research engines by reading the research papers and patents.
- Search engines do not waste resources.
- Thus, if they crawl, or trigger a sub-process, the output of the sub-process will be used for the next steps.
- Even if the previous step is not relevant anymore, the curated articles are used to define the entity with newly added information.
- Checking components in patents such as Ranking Engine, Indexing Engine, SERP Snippet Constructor is helpful to understand possible working principles and flows for web search engines.
The new entity’s subtitle is listed below.

The Turkish version of “Journalist,” which is “Gazeteci” is below, and it ranks “Dr. Emek Külür” from a newspaper’s streaming with a video content type directly.

At the end of the process, the “Journalist” is turned back to the “Dentist”, and two different “Dentist” related entity registrations and identity creations are performed. The important part here is keeping the two different entities separate from each other.
The reasons why Google didn’t consolidate these two entities are below.
- Both entity registrations have different definitions, and historical data, along with entity Knowledge Graph IDs.
- They have different entity homes.
- They have different connected other phrases, associated entities, and queries.
- The documents that link or mention these contexts, do not link others.
- The distinction between two different document clusters help for keeping this two separate.
In this example, the entity associations are enriched with the help of “Behzat Külür” who is the first husband of Emek Külür, and Yasemin Külür who is the daughter of Behzat Külür and Emek Külür.
- The creation of two different websites for both the Behzat and Yasemin Külür is planned.
- Both of those entities are mentioned, defined, and processed in different contexts for Emek Külür.
- The connections to the other unwanted entity are kept stale, and they are dominated by the new connections.
- The link graphs are completely different from each other for these documents.
- The attributes that are used, or definitions that are used are completely different from each other.
Thus, as below, two different “Dentist” entity has been created and used by Google.

Another important difference here is that 100% of the People Also Ask questions are changed. The question of “Why did Emek Külür divorce”, or “Why is Emek Külür divorced by X”, types of questions are turned into “Where is Emek Külür from?”, or “Who is Emek Külür married to?”, and “How many children Emek Külür have”?.

The “How many children” question is connected to “Yasemin Külür” whichis connected back to the “Diş Hekimi” which mens “Dentist”.

The “Who is Emek Külür married to” question connectedrelated to ex-husband, but Behzat Külür is here too.

And, by creating new news about Emek Külür and Behzat Külür, the two entities are brought closer to each other. The marked news in the image below tells that “Who is Behzat Külür”, and their marriage is defined as an event, and attribute for both of them. Thus, Behzat Külür is a related entity to the Emek Külür, and their “spouse” attributes show each other. Thus, the Emek Külür Named Entity has another attribute value for the Spouse which makes it fresher, and helps for focusing on non-magazine context, but continue to focus on business side of the entity.

If we search for the Yasemin Külür who is daughter of Emek Külür, the same context, and a heavier news and interview labeled content exist.

Directly the “People Also Ask” question mentioned Emek Külür with the title of “Doctor”, and allthe images are always together with the Emek Külür which strengthens the “mother” attribute visually with real-world signals. The articles that are marked below, and others were published during the Entity Identity Creation project.
The PAA questions show the direction of contextual connections too. For example, “Age of Emek Külür” is followed by “Age of Yasemin Külür”, and another “Doctor” with the name of Emek” which is a signal for distance from the magazine and love relationship themes.

The entity homes, family context, explanatory articles, interviews, news that mention “Emek Külür’s Daughter”, or “Emek Külür’s Family”, “Emek Külür’s Daughter Yasemin Külür who is also a Dentist” types of phrases are fed to the Google Algorithm. Even the “magazine” source in the highlighted area was directly and indirectly about the “dentistry” context.
To improve the specific project further, both of these associated entities that help with Entity Tiers for Definition should haentityve their own entity homes. The other entities that are used to define another entity are named “Class Signals”, for example” Yasemin Külür” signals “Mother” class, “Behzat Külür” signals “wife”, and all of them signal “Family” class. Thus, Class Signals should be corroborated with the main entity.
Why are Universal Search and Different Verticals of Search Important for Entity Identity Management?
The Universal Search and Different Verticals of Search Important for Entity Identity Management because it increases the confidence score of search engine for the presented statements and facts that are suggested by these statements. The search queries are satisfied by different types of content, such as audio, images, text, and animations, icons, illustrations, etc. Thus, the universal search represents different forms for the same fact. The entity identity creation and management should be holistic for every vertical of the search.
For example, if 5 different videos tell that the specific named entity “died”, but 5 different textual documents tell that the named entity still lives, and 5 other images tells that the specific named entity even didn’t exist at all, and 5 other audio files tell that the specific named entity is a cartoon character, it mgiht cause search engine to create 4 different entity registrations, or 0, or 1 with the highest possibility of safe answers.
- Because, technically, a cartoon character is not real, it didn’t exist.
- A cartoon character might die in this episode, but it can continue to live in the next episode.
- A cartoon character may live while a forum discussion claims that it is dead due to the words of a fired scenario writer.
- A cartoon character might be a reflection of a real-world character, and real-world character might continue to live, while the cartoon character died.
There are many example different information extraction, and points here based on the different verticals of the search. Thus, the entity identity management projects should continue from every angle.
In the Emek Külür SEO Project for Digital PR, Entity Identity Creation and Management, the Audio, Video, Image, Text content are used in News, Web, Image, Video, Audio sections, and Book section is planned with the Emek Külür Biography.
Why is Blurring the Identity for Information Foraging Important?
Blurring the Identity for Information Foraging is important because to change the established entity home, and the factual statements the, SEO needs to blur the existing consensus.
- If the consensus is not a consensus anymore, search engine will start to change the established facts.
- This is about Topical Authority, because topical authority SEO Strategy which is found by Holistic SEO, and Koray Tugberk GUBUR relies on defining the facts, and making other web sources irrelevant or only supportive for the factual information.
- It is a colloboration with the search engine to define the fact for the users.
- The Entity Identity Management and Creation projects should leverage the “consensus” theory by weaking the consensus, and creating a new one.
- If there are two different consensus for a fact, the entity homes and different entity identities are rised.
- To change the consensus about a fact, or a question, and entity for it, the document and query statistics are the methodological instruments.
- To blurr the entity identity, and provide consensus for a new entity identity creation, going direct opposite direction is not the efficient way.
- Blurr the definiions by adding them new connections, contexts, and angles.
- Ask questions that are not asked before for the entity, and start add new attributes, and values.
- Estabslih your own consensus in other languages, regions, verticals, and start to consolidate them with newly published documents and appearing search queries connectively.
Why is Using Other Search Engines important for Entity Identity Creation and Management?
Creating an Identity for an Entity while managing it requires focusing on every language, region, search vertical, content format, and every search engine. Entity Identity Creation and Management is not only for the Google. For example, Bing Pages is a Digital PR implementation. Google is the first social search engine that elverages the social media directly on the SERP, while helping people to represent themselves on the web pages of query search results. But, Microsoft Bing followed it to expand its own Satori (Knowledge Graph), and it provided a graphical user interface which is called Bing Pages for celebrities too.
- Celebrities with certain amount of follower base and search demand are accepted by the Bing Pages to be served in the Bing SERP.
- The Bing Pages provide an integration and connection between the celebrities and the searchers.
- Bing Pages are for making the Bing SERP a marketing tool for celebrities.
- Bing Pages are not fully launched yet, despite over 1 year is passed.
In the Emek Külür Projcet, the Bing Pages, and other search engines’ other types of features are used. For example, to prove the legit businesswoman identity of the named entity, the Emek Külür’s Businessplace and Brand Smile Institue has been added to the Yandex, Bing and Apple Maps, along with the Facebook Maps as a location pin. The results for Behzat Külür, Yasemin Külür, Smile Institue and Emek Külür are connected to each other in other web search engines, and their related and suggested queries on search bar, or the mid-page query refinements are altered to support scientific and business related contexts.

The Bing Pages’ registration screen is above, which is similar to Google’s Knowledge Panel Management system.
The Yandex Results for Emek Külür includes the “Diş Hekimi” which means “Dentist” at the top right Knowledge Panel, and it involves social media accounts, the ex-husband is not visible in the image pack mostly.

The video results hav scientific and professional content mostly, only one of them has the magazine context. The created podcast is served as opened with the timestamps and its own internal information.

The regular blue link results have the “Dr” and “Dt” which both means “Doctor” title, and none of them are magazine related.

The Emek Külür search results on Bing has the map-pack, image pack, and social media profiles, and professional results directly at the top.

The businessplaces, business related videos for the professional life of the named entity is directly served.

The regular blue title results directly from the Entiy Homes that we created, such as “Emekkulur.org”, and “Emekkulur.net”. It also demonstrates the SERP Diversification algorithms of Google. Because, Emekkulur.org and Emekkulur.net are not cannibilized with their own URLs, both of them appear 5 times as separate from each other with different results.
YouTube appears twice with the videos created during the campaign, as shown below.

One fo the example YouTube results are for the “Personal life and pleasures, and relationships of Emek Kulur” which is created by me to blurr the “love relationship” attribute consensus of Emek Külür in a positive way.

The second one is for “Dentistry Concepts” and they are directly from Emek Kulur, and her own understanding.
We also provide “poetry,” “sculptor”, and “family” life related factual information here. In other words, Microsoft Bing and Yandex made it easier to clean up all the magazine related articles. The important thing here is that, other search engines are used by the Google for troubleshooting their own algorithms.
- Google might realize that their Google DNS, or Gmails, YouTube, and Chrome are used the same intensity while certain queries lost their search demand.
- This is a signal that audience uses another methodology, or searhc engine for reaching out to related information.
- The query search demand decrease despite the internet usage is same signals a troubleshooting need for information retrieval, foraging, extracting and serving for search engines.
- Yandex, Microsoft Bing, DuckDuckGo are used by Googlers for engineering and comparison purposes.
- An optimized entity search engine result pages (Brand SERP) on Microsoft Bing and Google signals Google to gap between theirs and other search engines’ perception for an entity.
- Thus, it is important to show Google that, there is anew face of the entity that Google systems should paying attention to.
- The Google confessed that they are using Microsoft Bing for troubleshooting, and Microsoft Bing accepted they check Google.
- Today, Google Engineers test ChatGPT with millions of questions to understand how it answers questions, and how they can compete against it.
Why is Digital PR Important for Entity Identity Creation and Management?
Digital PR is important for Entity Identity Creation and Management, because it provides new consensus information, and corroboration pages for defining the entity, and associations with other entities based on semantic role labels, named entity recognition, and information extraction processes of search engines. Digital PR is not only for brand building, PageRank hoarding, sculpting, and authority building, it is also for changing the look of digital entities on the Brand SERP while creating and managing their entity identity.
Digital PR is used in the Entity Identity Creation and Management SEO Case Study based on the news sources, dentistry related blogs, law related blogs, business related web sources, business directories, social media accounts, podcast platforms, content sharing platforms.

For example, this SEO Case Study has been written in 3 months by showing the real human effort on every sentence, and researchpoint. During this time, the digital PR Campaign has continued. And, the marked section on the screenshot below shows a new Digital PR Article by defining the “Emek Külür”. And, in every new article, the “Vectoral Distances between the concepts, and entities” are changed, and co-ocurrance matrices are manipulated with legit sources to change the topical entities, context terms, and definition of the entity with new tiers, and attributes.
Why are Every File Types important for the Entity Identity Creation and Management?
Entity Identity Creation and Management relates to different file types because using different file extensions show the multi-publisher natural document statistics. The multi-publisher document statistic means that the published documents are not coming from a single source, which makes the consensus natural for defining the entity identity.
Using “pptx”, “pdf”, “html”, “webm”, “mp4”, “pdf”, “aspx” types of different document formats help search engines to gather information from different verticals of search, by using different file formats which increase the consistency for defining the entity naturally. The “pptx”, and different types of “slide” files are not used for re-defining the Emek Külür named entity, but it is planned. Having professional and scientific PDF files, and PPTX files on a website helps for further rankings, which is proven during SEO A/B Tests, and implementing PDF SEO for these files is useful too.
Lastly, possible cannibalization between the search engine result page snippets and URLs from the same source is decreased in cases where the document format and file extension is different. Thus, using different web source document extensions is implemented in the Emek Külür SEO Case Study.
Why is Using Diferent Authors important for Entity Identity Creation and Management?
Using Different Authors is important for Entity Identity Creation and Management because the word sequences, and vocabulary changes between the articles represent the multi-source web publication, which signals the naturalness of consensus. For example, writing 50 different articles about a named entity, and always using the same sentiment, context flow, word sequences, adjectives, predicates, and statistical linguistic signatures is harmful to the trustworthiness of the documents.
Search engines are able to recognize the true author of a document by creating author vectors, and stylometry. The Generative AI Systems use the statistical signatures and watermarking technologies to state the AI system behind the content that is an output of a Large Language Model (LLM).

In the Emek Külür Entity Creation and Identity SEO Case Study, different writers are used for every article so that there is no direct overlap in the wording of the articles. Some of the articles are published badly on purpose so that the natural background can be established. The publications are linked to each other, along with links to the different contexts, and entities that are distant from the “ex-husband” and “ex-boyfriend” themes and angles.
While using the different authors, paying attention to the word “proximity” for “proximity search” is important. Thus, some of the rules below are implemented.
- Pay attention to the words to the left and right of Emek Külür.
- Paying attention to what other entities appear in the Macro Context area of the web documents.
- Organizing the text around the anchor text to create a more natural click navigation design that does not use pushy language
- When defining the entity, avoid using sentimental or overly marketing language.
- Always using consistent information for dates, places, or ages, and career related information.
- Changing the predicates, adjectives and noun chains per article, while keeping the words that come after “is” consistent.
To keep SEO environment healthy, this section will be explained further in the Semantic SEO Course.
What are the Search Engine Result Page Samples for the Entity Identity Creation and Management SEO Case Study?
The search engine result page samples for Entity Identity Creation and Management involve SERP screenshots from different sections of the and times of the case study. These samples are from different SERP segments whether it is Local Pack, Local Business Knowledge Panel, or Related Search Queries.
The 8 different related search terms for Emek Külür involves “height”, “biography”, “forum”, “age”, “instagram” types of context directions. Only two of them involve the “husband”, one of them gives a result for “Behzat Külür”, the other one is directly for the “other ex-husband”.
Due to two different “ex-husband”, there are related search terms like “Emek Külür first husband”, “Emek Külür husband”, which is a signal for “entity identity blurr”.

Today, the related query terms are nearly the same, but their rankings are different which signals that the “personalized” information is more important than before.

The “local pack” for Emek Külür’s business is used to expand it further and further with the new information. The new reviews are added to the Local Map Pack.

The type of the “Google Business Profile” has been chosen as “Cosmetic Dentistry” so that the entity can be classified better and more relevant to dentistry.
The Google Posts on the Google Business Profile has been used to add more SEERP Estate and SERP Control over the coverage of the entity with the contexts that are related to the professional lifestyle.

In mobile search experience on Google, the Google Posts carousel creates the difference a distance between the magazine and professional news, and pays more attention to the entity identity tiers, and attributes that are relevant to business, and professional life.
The services, products, phoen numbers, website address, and many other attributes such as questions and answers are added to the Google Business Profile, and they should be enrichened further for a better Entity Identity Creation and Management.


The SERP sample above demonstrates how certain results are removed due to legal reasons, It says that “Some results are removed due to legal warnings.” It directly indicates the effort for changing the document statistics, which provides a safe answer range for Google to use in the future.
To improve the Google Business Profile, and Local SEO Practices for Entity Identity Creation, the local map packs from different search engines, dentistry-related business directories, and dentistry-related pins from Pinterest or other platforms are interconnected with each other.
Other SERP Snapshots during the project to show the difference in all search engines over time, including related search terms, regular search results, autosuggestion, videos, and maps are below.

































































What are the Spammy Examples for Entity Identity Creation and Management?
The Spammy Examples for Entity Identity Creation and Management involves examples from different search engine optimization practices, such as black hat. The purpose of the spammy practices for changing the SERP involves creating fake business directories, or fake adult content to harm the identity of the business.
Both of these spammy examples are given in the Video SEO Case Study, and not included here due to certain constraints.
But during the SEO Case Study, the other party who tries to harm the reputation and distort the definition of the digital entity used fake news, and adult misinformation, thus, the Entity Identity Creation and Management SEO Case Study involves certain practices for fighting back for Anti-SEO campaigns.
Why is DMCA Requests useful for Entity Identity Creation against Spammy Results?

To save Digital Entity Reputation, using DMCA Removal requests is a method that fasten the process of optimizing the document statistics properly. The Content Removal request via DMCA can involve “duplication”, thus creating a controllable duplicate content as it is the original one is useful to force Google Systems to remove the non-controllable request. DMCA Systems of Google is strict since it removed the Reddit Homepage due to an appearance of DMCA complaint related documents before.
In the Emek Külür SEO Project, the DMCA Complaints are used successfuly for removing some of the results and change the document statistics. The DMCA complaints are a direct and a hybrid method for legal context for removing content to change how a digital entity is presented on its own Brand SERP for SEO.
What is SERP Estate Control for Entity Identity Creation and Management?
SERP estate is a concept to define and express the estate that a web source covers on search engine result pages as pixels, and features. For example, a web source might rank 40% of the targeted search terms with a 5 average position, but it might not have most of the SERP features, and some competitors might have a more covered pixels on the SERP estate.
To optimize the SERP Estate, using different types of web content formats, and structured data like FAQ is helpful. For example, FAQ Structured data helps by adding extra related questions and answers from the document to the search query results by covering more SERP estate in terms of pixels. In terms of the SERP features, ranking on the Image Pack, Local Map Pack, being mentioned in related terms, or auto-suggestions, and ranking on regular results and featured snippets, or PAA sections of the SERP are practices for optimizing SERP control.
The entity profiles, local business panel, and it’s about the business, questions, appointments, Google Posts, and curated web sources and web entities are given below to show the SERP Estate Control and Optimization results.

Why is PageRank Important for Entity Identity Creation and Management?
PageRank is a algorithm to measure the importance and reliability of a web page in an internal link graph based on the links’ quality, relevance and counts. The PageRank is important for Hypertextual Search Engines like Google to determine the authority and quality of a content. The Topical Authority and Semantic SEO balance the PageRank for understanding the real authority of a web source. The PageRank algorithm and signals are important for the Entity Identity Creation and Management, because web sources with higher topical relevance and authority along with PageRank are easier to use for representing the entities, their identities, and being served inside the Knowledge Panels.

The web sources inside the Knowledge Paneles are seed sources, or individual official websites for certain entities, and their classes. Thus, suing web sources such as Crunchbase for Investors, and IMDB for actors and actresses are helpful for using PageRank and Authority to redefine the web source. In this case, the Barnacle SEO and Surroundsound Concepts are used in Entity Identity Creation and management, because to change the idea of a serch engine for a entity, making changes on seed sources such as Wikipedia, Crunchbase, IMDB are needed. Having authoritative accounts, and historically proven quality for the accounts on these platforms are useful to give better signals to a search engine in a consolidating way to earn the trust of search engine.

In the Emek Külür Entity Identity Creation Project, the authoritative sources are not used due to budget constraints and high inflation in Turkey. This was the biggest obstacle and constraint in entire SEO project, but thanks to high level of search engine understanding, and authoritative, semantically optimized content network creation, the low PageRank sources outranked the high PageRank magazine sources while changing the most of the SERP. The residue of the old results are due to high PageRank and long historical data that can be overwritten by the new content from the same web sources, or new content from the same-level PageRank and topically relevant web sources.

The three entity homes that are created and managed do not have a proper level of PageRank, but still they function due to content relevance and responsiveness. The results below are for the corroboration of web sources and pages.

T54 is one of the sources, and as you see it doesn’t have a proper PageRank, or traffic.

YurtGazetesi is another web source, but it doesn’t have a proper traffic or PageRank value.

The Rayhaber is a local web source for news without a proper PageRank and centrality on the nation-wide news channels.
The web source below is from another party with 11,200,000 traffic, and 13,900 referring domains which is way much more authoritative than the sources that we use.

The second opposition web source with high level of historical data has 73,600,000 organic clicks a month, and 42,700 referring domains which is a signal for high level of authority for news.

These two are examples of residue sources that are from the past state of the Brand SERP. And, it shows the PageRank difference between the web sources that we use and the opposition.
The specific residue web sources are news sources with over 10 years of historical data for the specific named entity. Thus, dominating the News Vertical of the SERP has been chosen as the first target of Entity Identity Tier change, and SERP Estate control.
Last Thoughts on Entity Identity Creating and Management
The Entity Identity Resolution is observed in “text-to-image” models in a visual way. For example, the image below has 8 different sub-images within it. The four on the left are from the sentence, “Google as a Turkey.” The images on the right are from “Google in Turkish.” The prompt engineering is an important concept for manipulating the output of Generative Artificial Intelligence. The specific Generative AI system for the generated images below is Midjourney which is developed by David Holz as proprietary software as open-source. The prompts that are used “Google as a Turkey ” and “Google as a Turkish ” reflect the Midjourney’s data-set for uniting two different entities, one from as a company, the other one as a country. But, the data-set relates the phrase “turkey” with the animal entity, and


- Sliding Window - August 12, 2024
- B2P Marketing: How it Works, Benefits, and Strategies - April 26, 2024
- SEO for Casino Websites: A SEO Case Study for the Bet and Gamble Industry - February 5, 2024

Wow. Im speechless. Koray, you know you are absolutely incredible for sharing all the SEO case studies, but this one is just unbelievable. I said multiple times how mindblowing every single one of your researches are, but this…. This is next level, like, another-dimension next level. Semantics are like a “special language” that allows communication with the neural network of a supercomputer’s brain… I think after reading this case study people can confidently change their titles from “SEO expert” to “ai-brain neurosurgeon” 😀
Thank you so much for your kind words, Pavel. You are a true hope for the SEO industry.
In Turkish: Yazıyı yarısına kadar okuyabildim. En etkileyici kısım “Kimin neyi tıklayıp kimin hakkında hangi açıklamayı öğreneceğine, karar vereceğine ve inanacağına biz karar veririz.” yanıtınız olmuş. Türk bir gencin avrupalılara ders verdiğini görmek beni gerçekten gururlandırdı. Yıllardır belli başlı forumlarda edu ve gov uzantılı sitelerden yorum backlink, ücretli haber sitelerinden takas footer backlink almaktan başka kendimizi gelişteremediğimiz için başarılı birini görünce gözlerimiz doluyor inan. Türkiye’de seo uzmanıyım diyerek millete fahiş fiyatlarla hep bilindik eğitim paketi satan malum şahıslar gibi değil, dünyaya bir Türk’ün bu sektörde var olduğunu kanıtladığın için seni gerçekten tebrik ediyorum. Ben “Matt Diggity” ile olan videonu gördüm ve gerçekten gurur duydum. Hakkında her zaman her şeyin hayırlısı olmasını diliyorum. Başarıların daim olsun.
The Translation of the Comment: I could only read half of the article. The most impressive part is “We decide who clicks what and learns what explanation about who, decides, and believes.” you got your answer. It really made me proud to see a Turkish young man teaching Europeans. For years, we can’t improve ourselves other than getting comment backlinks from sites with edu and gov extensions in major forums, and swap footer backlinks from paid news sites, so when we see a successful person, our eyes fill with tears, believe me. I really congratulate you for proving to the world that a Turk exists in this sector, not like the people who sell well-known training packages to the nation at exorbitant prices by saying that I am an SEO expert in Turkey. I saw your video with “Matt Diggity” and was really proud. I wish all the best for you always. May your success always be.
Merhaba Oğuz,
Öncelikle, bu kadar nazik sözler ve destek için çok teşekkür ederim. Başarımın sizin gibi kişiler tarafından fark edilmesi ve takdir edilmesi benim için büyük bir onur. SEO’nun karmaşıklığı ve sürekli değişen yapısı, hepimizi sürekli öğrenmeye ve kendimizi geliştirmeye zorluyor.
Her ne kadar çeşitli başarılara ulaşmış olsam da, her zaman yeni şeyler öğrenmek için çaba harcamaya devam ediyorum. Bu sektörde kesinlikle daha fazla Türk yeteneği olduğuna ve daha birçok başarı hikayesi yazacağımıza inanıyorum.
Bu nedenle, SEO’daki başarılarımı sadece kişisel bir kazanım olarak değil, aynı zamanda Türkiye’nin genel başarısını ve yeteneğini gösteren bir fırsat olarak görüyorum.
Dediğiniz gibi, belli başlı taktiklerin ötesine geçmek ve gerçekten değerli, özgün çalışmalar ortaya koymak önemli. Bu durum, hem bizim bireysel olarak gelişimimiz için, hem de genel olarak Türkiye’nin SEO alanındaki başarısı için geçerli.
Her zaman öğrenmeye ve kendimizi geliştirmeye devam etmek önemli. Hepimizin, kendi başarımızı ve SEO alanındaki genel başarıyı artırmak için bir arada çalışabileceğimize inanıyorum. İyi dilekleriniz için tekrar teşekkür ederim ve sizin de başarılarınızın devamını dilerim.
Translation of the answer:
First of all, thank you so much for such kind words and support. It is a great honor for me that my success is recognized and appreciated by people like you. The complexity and ever-changing nature of SEO forces us all to constantly learn and improve ourselves.
Although I have achieved various successes, I always make an effort to learn new things. I believe there is definitely more Turkish talent in this sector and we will write many more success stories.
Therefore, I see my success in SEO not only as a personal gain, but also as an opportunity to demonstrate Turkey’s overall success and talent.
As you said, it’s important to go beyond certain tactics and produce truly valuable and original work. This is true both for our individual development and for Turkey’s success in SEO in general.
It is important to always keep learning and improving ourselves. I believe we can all work together to increase our own success and overall success in SEO. Thank you again for your good wishes and I wish you continued success.
Thanks. I enjoyed reading all of it. Huge effort to change Google’s understanding of an entity.
An interesting find was a patent for LLM watermarking. Is there another case in which to read more about this?
There are more cases as this one, but I could not find enough time to write it.