
Initial ranking score and historical data for SEO are two useful concepts to understand a website’s (source) potential to be able to rank for a query network, phrase variations, or topical cluster initially. Initial Ranking and Re-ranking are two different phases of the ranking process of Search Engines. Understanding Initial Ranking and Re-ranking Processes, and Search Engines’ perspective for ranking related processes, is important to be able to initially rank a source for a query network better.
Initial-Ranking and Historical Data Importance for SEO are mainly connected to Semantic SEO along with Technical SEO, Web Page Loading Performance, Source Popularity, and Reputation. During the Initial-ranking and Historical Data SEO Case Study, four websites will be given as an example. These websites’ names and their organic search performance change during the SEO Case Study can be seen below.
- 10,000 Queries, Daily 300 Clicks, 40,000 Impressions in 20 Days (Initial Ranking), İstanbulBogaziciEnstitu.
- 33,000 Queries, Daily 11,000 Clicks, 150,000 Impressions in 65 Days (Re-ranking), İstanbulBogaziciEnstitu.
- 3,500 Queries, Daily 200 Clicks, 2100 Impressions in 30 Days. (Initial Ranking), Vizem.net.
- 32,000 Queries, Daily 5,000 Clicks, 54,000 Impressions in 30 Days. (Re-ranking), Vizem.net.
- 416,000 Queries, Daily 2,000 Clicks, 890,000 Impressions in 45 Days. (Initial-Ranking), Site-3 (Not disclosed).
- 185,000 Queries, 1000 Clicks, 201,000 Impressions in 6 months. (Initial-Ranking), Site-3 (Not disclosed).
One of the newly (entirely) published websites’, how it is ranked initially, and how it is re-ranked by the search engine can be seen below. This example is from Site-3.

The example below is also for the same website and its increase in terms of organic search performance.

Another example can be seen below.

The last situation of Vizem.net can be seen below.

After 30 days, this is the last version of Vizem.net from the Semantic Content Network SEO Case Study.

The three weeks later versions can be seen below.

The last situation of IstanbulBogaziciEnstitu.com can be seen below.

Vizem.net’s last situation can be seen below.

This is the 30-day later view of Vizem.net for the Semantic Content Network SEO Case Study.

The Videos to Explain How Google Ranks are presented below. Semantic SEO Strategy to convince Google’s ranking algorithms is presented below.
An algorithm analysis for Google’s Ranking Systems is below.
450% Increase in 3 Month: From 60,000 to 330,000 / 2,000 to 11,000 Daily/Monthly Clicks – İstanbulBogaziciEnstitu
The first website’s industry is education for students, workers, employees, and any person from daily life with every kind of possible skill improvement. Since the first website is about “paid course selling”, it is easier to find proper query templates, intent templates, and document templates to create a contextual attachment between the query and the document around a specific topic and interest area. Most of the queries include a verb when it comes to improving a talent, or skill via a paid course such as “coding, convincing, managing, concentrating”, and they also include a context with a noun, or object such as “business, motivation, software, resources”. When these different contexts are combined based on a topical map, they can consolidate the expertise and categorical quality of a source for better initial ranking.

During İstanbulBogaziciEnstitu ’s SEO Project, the advantage of the initial ranking has been used from day one. The organization of the information on the open web by a search engine can be perceived by the search engine’s preference for ranking the documents and clustering the queries, and sources along with contexts. Based on this, for the first website of the “Initial-ranking and Re-ranking SEO Case Study”, the methods below have been used.
- Choosing a contextual gap between the educational websites and the audience for the specific topic.
- Deciding the best possible centroids for the clustered queries from the specific topic.
- Generating the best possible query templates.
- Generating questions from the query templates.
- Matching the answers with the generated questions.
- Connecting the different contextual domains to each other based on related search activities.
- Creating the content network as ready to be opened to the Google Search Engine.
- Letting Google index all the content networks by noticing “strongly connected components”, and attached “contextually matching queries and documents”.

During the first website’s SEO Case Study, I noticed the things below.
- The documents from the content network that are placed higher, and earlier indexed faster than the delayed articles. If a document has been linked before then others within the seed page, and if the “local interconnectivity” of these pages supports this order, it will be indexed than others.
- The first indexed documents have changed their rankings in a faster way than others. In other words, the “re-ranking” has been triggered earlier than delayed documents within the content network.
- If for certain types of entities, the source doesn’t have enough historical data, the initial ranking will be lowered.
- Google can index the same amount of URLs with certain day breaks. It shows that Googlebot creates a frequency and regularity for the indexing. And, when the first indexed pages are successful to overcome the quality, relevance, and accuracy threshold, search engines will increase the frequency and velocity for indexing by decreasing the crawl delay.
- Seasonal Events can be used for triggering a re-ranking event.
- A seasonal event can include multiple trending topics, and clustered queries, if a new source publishes a new content network with high quality for the specific topic with high accuracy, search engines will prioritize the indexing documents from the same topic while refreshing the old content from its context.
- During this prioritization, a new source can have the benefit of creating historical data for the specific topic, and this historical data will help for further indexation, and improve the overall quality, and organic search performance.
- Having high impressions from certain types of trending topics, and related queries will improve the average position of the related documents. These documents will protect their rankings if they are successful to overcome the quality threshold by providing better structured factual information organization than existing competitors.
Below, you will find the specific seasonal event, and its effect on the average position and total click count.

On Jun 9, 2021, the related content network has been opened to Google.
The targeted seasonal event was on 28 July.
- The target was to have the seasonal SEO Effect for gaining the trust of the search engine by gathering all the historical data possible.
- To do that, the contextual vector, hierarchy, neighborhood content, and knowledge domain terms are arranged with related information and facts.
- Sentence structures, the related entities, and contextual bridges across the topical map have been created.
- The contextual hierarchy is provided with related taxonomy, and also related search activity for the specific topic’s subtopics.
- Until 28 July 2021, search engines were indexing between 5-25 pages a day.
- After 28 July 2021, it was more than 100 per day, and soon after, all subsections were indexed.
- Before the seasonal SEO Event, there was an unconfirmed Google Update.
- This specific update was a test for the source, and it is not affected permanently.
- The average position before the seasonal event was between 11-13.
- During the seasonal event, the average position was 7.6 since Google prioritized the relevant sources.
- After the seasonal event, the average position was between 9.0-10.
- There was another unconfirmed update on the first day of September.
- Until and during the unconfirmed update, the seasonal SEO event’s effect continued, but Google tested the source one more time.
- During the update, the average position was 13.8, and the daily average click has dropped to 3,000 – 4,000 from the 12,000.
- After the unconfirmed update of Google from the first day of September, it was 28,000 daily clicks with an average position of 8.
- During the 5-6-7-8 of September, there was another sequential unconfirmed Google Updates, and Google has normalized the traffic and the average position as 8.6, and the average clicks per day were between 12.000-13.000.

A comparison of the 2020 September and 2021 August shows the true change of the SEO Project in the best way.
This is an example of using the historical data, the initial-ranking advantage with high coverage, and first-day comprehensiveness for a topic by triggering a re-evaluation for all sources during the unconfirmed updates. And, the sections above explain how Google has tested the source thanks to a seasonal trending event and re-ranked the source for further testing.

The comparison of 2020 July and 2021 July.
When enough historical data, and “implicit user-feedback” have been provided, the source has ranked last time with a high confidence score as after the seasonal event with nearly the same average ranking and click amount.

The comparison of March 2021, and August 2021.
Below, you will see the changes in the daily crawl requests for İstanbulBogaziciEnstitu during the SEO Case Study of Initial-ranking and Re-ranking examination.

There is a gradual increase in the crawl requests and the total download size. After the Seasonal SEO Event, the gradual increase continued. And, the unconfirmed Google Updates’ correlation with the requested amount of Googlebot can be seen. Since the crawl data from GSC is partial, still performing a full analysis is not possible, but acquiring the log data for every SEO Project for a log analysis might not be possible.
The indexation process can be seen below.

The “total crawl requests” and the “impressions”, and the “indexation” process, along with the “unconfirmed updates of Google” has an alignment. During the SEO Case Study, you can see the change from SEMrush as below.

The change and the success can be seen from Ahrefs as below.

Below, you will see the change only for the published content network.

All this change happened in 3 months. The same content network can be seen from SEMRush as below.

While I am writing these lines, I have published another topical map with sub-topics that are related to the content network that I have published previously. Below, you will see the graphics for only the newly published content network. And, these graphics are from the second day of launch.

From Ahrefs, the second day of the new published content network can be seen below.

From some videos, I actually have some view of the first day, 7th day, and 20th day of the previously published education topical map’s success based on Semantic SEO practices with initial ranking. Below, you can see the images of the first published content network’s success and change for the first 20 days.
1
2
3
I am showing both of the content networks’ existing and previous versions because they are similar. Once, three months ago, the educational topical map didn’t have even a single query within the first 3 rankings. With 0 backlinks, only with SEO Theories and Search Engine Understanding, it has more than 1500 queries in the top 3, and more than 32,000 queries in total in 90 days.
In this context, let me explain the initial-ranking advancement. Above, we have processed the average position changes during the indexation of the education topical map (first published content network) and we compared it to the different timelines to show how the confidence judgment of search engines changes. In this context, below, you will see the initial ranking of the new published content network which focuses on “jobs, and occupations”.

This is a screenshot from the first 7 days of the related subfolder, and it has an average of 6.5 positions. It is two times better than the initial ranking of the content network that focused on “education”. The second content network has a topical map for the “jobs and occupations”. As you can see, the “jobs” and the “education”, “skill improvement”, and “career advancement” are related to each other. And, semantically created topical map hierarchies, and aligned content networks with knowledge domains, contextual domains, and layers are supporting each other by making the same source more authoritative.
Below, you will see the initial ranking of the “educational topical map” which is the first content network that I launched on 9 June 2021.

You can see the improvement of Topical Authority and its reflection on the initial ranking. Since I love to focus on theoretical concepts of Search Engines, I will process the “initial ranking”, and how it can be improved, how to generate the content templates, based on interest areas and query templates, or how to connect different content networks to each other. To plan a topical map, to catch a seasonal event, to gather historical data, and convince the search engine with comprehensive information and high topical coverage, semantic SEO and search engines’ nature should be known by SEOs.
Broad Core Algorithm Update and Unconfirmed Google Update Effects on the İstanbulBogaziciEnstitu
A Broad Core Algorithm Update can change the overall relevance radius and ranking efficiency of a website. A search engine can change the crawl priority, indexing delay, and a confidence score for rankings with a Broad Core Algorithm Update. Websites can experience a relative improvement after a broad core algorithm update thanks to an Unconfirmed Google Update, but reversing the entire effect of a Broad Core Algorithm Update can happen with another Broad Core Algorithm Update. In the context of re-ranking, and initial ranking, both of the algorithmic update types, whether it is an Unconfirmed Google Update such as a Phantom Update, or Broad Core Algorithm Update (BCAU), can affect the initial ranking and re-ranking processes, assignments, and potentials along with the relevance radius.
The Google Broad Core Algorithm Update from June affected İstanbulBogaziciEnstitu negatively. It means that all the values that have been seen from above could be way much better than the actual values since Broad Core Algorithm Updates affect the initial-ranking potential, and re-ranking processes’ negativity or positivity.
Below, you can see the negative effect of the June Broad Core Algorithm Update for İstanbulBogaziciEnstitu .

Since the website has acquired a tremendous amount of organic traffic increase shortly after, the negative effect of the broad core algorithm update can’t be seen clearly. Below, you can see its negative effect a little in clarity.

A Broad Core Algorithm Update can be won by a website even if it loses organic traffic for the previous time, or it can be lost even if the website increases its organic traffic for the previous period. A broad core algorithm update can slow down the rankings of the articles that will be published after the update’s launch, or it can improve the initial rankings. A relevance radius, prominence score, and quality score for the overall source can be recalculated by re-distributing the source’s position on the query clusters based on topical borders. In the example of İstanbulBogaziciEnstitu, despite the negative effect of Google’s June Broad Core Algorithm Update, the website is able to rank better than sources with authority, historical data, and relevance for a specific topic thanks to Semantic SEO implementation.
Further Information on the Second Content Network Launch
While writing the Initial-ranking and Re-ranking SEO Case Study and Research, I was able to check the second content network’s initial-ranking process with continuous re-ranking. Below, you can see a video from three different sources with the daily improvement.
Google Search Console Data for the Second Content Network’s first 10 days can be found below.

When the query count increases, the positional data for the specific queries change. Whenever more web pages are indexed for more queries, the average position decreases, after collecting the necessary amount of historical data and relevance consolidation from the content network, the average position rises again with the help of a positive re-ranking effect. You can see the relevance of impressions and the average position with the same perspective.

The re-ranking decay for a web page from the semantically created and configured content network is lower than the previously created and relevant to the second one thanks to the source’s improving historical data and confidence score of the search engine.
- An inverse proportion between the average position and the increasing impression means that the source shows itself for more queries.
- And, if queries, impressions, and average position increase together after a short period of time, it means that the re-ranking happened after the initial ranking.
Ahrefs Data for the Second Content Network can be seen below only for the first 10 days.

Some key points from the Ahrefs data for the second content network’s first 10 days can be found below.
- Taking the queries for the first 3 rankings with the first content network has taken 60 days.
- With the second content network, it has taken only 10 days.
- This “re-ranking positive effect” and “re-ranking decay” are the signal of the topical authority increase.
SEMRush Data for the Second Content Network can be seen only for the first 10 days.

Below, you can check the first content network’s overall performance for the last 3 months.

From zero to 712,000 organic clicks can be acquired with semantic SEO and “Initial-ranking” advantage. And, nearly 15% of these organic clicks are acquired in a single day for the historical data advantage and a faster re-ranking process.
What are the Last Situations of the Content Networks that are Published?
Since I do not know when I will publish this long SEO Article and Case Study, I have put this heading here. You can see the last situations of these sections below.
The last Situation of the first content network is below.
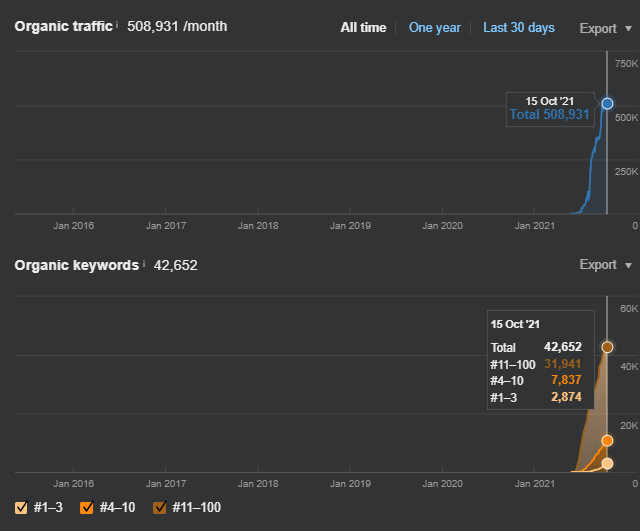
The last Situation of the second content network is below.

15 October 2021, the performance of the Second Semantic Content Network of İstanbulBogaziciEnstitu which is the 19th day of the launch.
The third semantic content network’s potential is larger than the first two in terms of the topical coverage and the search activity frequency, thus, with the support of the first two semantic content networks, the third one can have more than 200,000 queries alone with more than 1.5 million organic sessions. Since it won’t have a detailed configuration and semantic closeness, the actual numbers will be lower than they should be.
In normal conditions, only this SEO Experience deserves a separate article, because there are way much more details. If I do not publish this article, I will put the change of the second content network that focuses on the jobs and occupations as well below with an extra note. Or, I will add it later.
Now, we can focus on the website which has a different methodology that has been followed for initial ranking and the better re-ranking processes.
From 0 to 10.000 Daily Organic Clicks in 6 Months – Vizem.net
For the second website, I can’t write a proper organic click increase percentage since it comes from 0. On Vizem.net, the methodology that I use for the initial ranking and the re-ranking are entirely different. And, to explain these differences, I will need to explain the knowledge domains, contextual domains, context qualifiers, query templates, question-answer pairing, and entity association based on entity types, related-possible search activity coverage, search intent coverage, query paths, broad appeal, and more. Since my main focus here is “re-ranking” and “initial-ranking”, I will explain some of these terms based on “ranking” algorithms of search engines in future subsections.
What is the background of Vizem.net?
Vizem.net is a Visa Application Website. The website doesn’t have a specific purpose in terms of country, region, or visa-related process. The client wants to cover everything for a specific industry, which is a great advantage for the “Broad Appeal” which is a quality signal. Based on this, the Query Parsing and Processing methods of a Semantic Search Engine are used to understand the importance of the attributes and possible search activities based on them.
Query Parsing and Processing methods of a Semantic Search Engine rely on named entity recognition, phrase-based indexing, co-occurring matrices, word clusters, word vectors, and semantic role labels along with fact extraction about entities. In this context, to create a proper topical map for topical authority, a person should be able to find the mutual parts of queries, their possible templates, and “next word-sentence prediction” algorithms’ reflexes. After the query parsing and process analysis, the important part within the queries was “countries”. And, all the taxonomy and ontology have been used based on entities with the type of countries.
To keep things around the “re-ranking” and “initial-ranking”, I won’t go deep on the topical map creation, and query processing. To learn more about query parsing and processing methods of a search engine, you can read one of the related presentations.
What are the methodological differences between İstanbulBogaziciEnstitu (Site One) and Vizem.net (Site 2) SEO Case Studies?
Vizem.net’s main methodological difference from the İstanbulBogaziciEnstitu is…. Continue
What is Initial Ranking for SEO?
Initial ranking is the first assigned ranking value to a web page for a query within the Search Engine index. Initial Ranking can be changed during the re-ranking process by the Search Engine, according to the changes over time for the document based on internal or external factors. Initial ranking value for a web document can affect its historical success and discoverability itself. Based on this historical data, the re-ranking scores will be altered by the initial-ranking score irreversibly. Thus, an initial ranking score is important to make a web page document successful and ranks it higher on the surfaces of a search engine.

Every web source can have a different average initial ranking score for a different topic, query pattern, entity, or context-based on its topical coverage, authority, and popularity. Historical data for a source can affect the initial ranking score for the web page documents that belong to the source. If there is high historical data with positive user feedback, and relevance, quality, and reliability signals, the initial ranking score will be boosted furthermore.
To boost the initial ranking score of a website without historical data, topical authority, and popularity for a query network, broader appeal, deeper information, and faster topical map completion can be used.
What is Initial-Ranking Potential for a Source?
Initial Ranking Potential is the potential of a source for increasing its initial ranking value for a topic, query network, or phrase variation based on its historical data, topical relevance, authority, and click satisfaction evaluation. Initial Ranking Score and Potential can be perceived, be affected, and affect the things below, in the context of SEO.
- Same textual and visual content can have different initial rankings within different sources.
- The same textual and visual content can be published in multiple sources, and Google can assign the one as the canonical version based on the initial ranking score.
- Initial ranking score and potential can be increased by updating, and publishing content more frequently for a certain topic.
- Topical coverage, topical authority, and topical relevance are directly related to the initial ranking score.
- Source authority, popularity, and reliability-trust signals can affect initial ranking potential.
- An initial ranking score of a source can impact the source’s re-ranking process and indexing delay.
- The initial ranking potential of a source can be measured by the initial ranking of a document from a source for a specific, certain type of query.
- The initial ranking score can be influenced by the Page Speed, Technical SEO, grammar structure, and overall quality score of the source.
- Initial-ranking score and potential can increase after a Broad Core Algorithm Update for a source.

Full Domain


How Does Initial Ranking Work for SEO?
Initial ranking score (value) assignment for a source can affect different HTML, PDF, CSV, or PPX Documents’ rankings on the SERP. Based on this, Initial Ranking for SEO can be used to boost a website’s initial ranking for better organic search visibility. For websites such as News Sites, Blogs, E-commerce, or Affiliate Sources, an initial ranking score can be used to rank these websites’ documents faster.
To rank content faster with better rankings, initial ranking concepts and scores can be used to understand the Search Engines’ perspective. The overall quality of a website and clarity can help a Search Engine to assign a source with better initial ranking potential for the documents of the website. Thus, for certain topics, contexts, entities, and queries, some sources can be ranked initially with higher rankings. To use and measure the Initial Ranking Score for SEO, the methods below can be used.
- Auditing the initial ranking of a source for a specific topic.
- Checking the synonyms, phrase variations, and related queries for the initial ranking of the document.
- Checking the re-ranking process, speed, and direction for the document.
- Comparing different categorical queries and documents for the initial ranking value.
- Checking the competitors’ initial ranking.
- Auditing the indexing delay for certain topical content.
- Checking the partial indexing and rendering phases of a document with the Search Engine perspective.
- Improving the neighbor content, publication, and update frequency for the information amount on the source for a certain topic and website segment.
- Decreasing the average web page size to decrease the crawling, and indexing cost.
- Increasing the source’s popularity and reliability, along with its reputation.
- Completing a topical map by covering more topical nodes faster than competitors.
- Improving the source size with unique content, information, and sentence count faster than competitors.
- Using the front-title words for checking the average initial ranking value and potential of the source.
A high initial ranking score will decrease the time decay for the re-ranking process and its positive direction intensity.



Why is the Initial Ranking Score useful for Search Engines?
The initial ranking score can decrease a search engine’s time and resource cost for the evaluation of a document to rank it. Initial Ranking Score Assignment can rank documents on the web more efficiently. High Initial Ranking Score Assignment can be used for the authoritative sources for different topics. Topical Authority Assignment and Semantic Clustering of the information on the web complete the Initial Ranking Value for sources and documents.
Google uses Machine Learning algorithms to allocate Web Crawling Resources to different sources, and also source sections. Initial-ranking scores can be different for different web source sections. The initial ranking score assignment for different website sections is below.
- A Search Engine can assign a high initial ranking score to an eCommerce website’s specific product pages for specific product types, and features while for the informational content on these pages, different website sections can have a lower initial ranking score.
- A Search Engine can try a source by increasing its initial ranking score and evaluation to see the source’s link proposition value.
- A Search Engine can assign high initial-ranking scores for certain keywords, entities, attributes, or query patterns for certain source sections.
- A Source section can be determined by author name, web page layout, URL or Breadcrumb breakdowns, Structured Data, or question and answer format of the content.
- A Source section can be evaluated based on the external references, whether it is a link, mention, or referenceless quote from the original source.
- A Source can have a better initial ranking score for specific sessions or seasonal trends based on its source identity, or source section identity.
- A Source’s initial ranking can be affected based on the visual content, or visual content material for specific site sections. A query can seek a video, image, infographic, or visual explanation, and representation. If a source section has more visual content than others, it might have a better initial-ranking score for these types of queries, and questions.
- A Source section can have a better or lower initial-ranking score based on the unique sentence count, unique paragraph count, unique content count, or grammar errors, writing style, and unique terms, information, facts, prepositions, and structured opinions with numeric values, and statistics.
- A Source can be clustered with other sources based on links, content similarity, webpage layout, or organizational and entity profile features. If a source is clustered with other sources, the initial ranking factor can be evaluated together with other sources.
- A Source’s different sections can be clustered with different sources. If a source’s news section is closely related to a specific news site, while the recipe section is closely related to a recipe site, and if the blog and product sections are closely related to other types of sites, the initial ranking evaluation process can be handled by different clustering processes. To modify the initial ranking score of a Search Engine, a source should target to become the representative of the quality source clusters for specific topics, and contexts.
Thus, an initial-ranking score is helpful for Search Engines to understand the web faster, and introduce the new web documents to the web search engine users within the query results with the best relevant results. If a source is authoritative for a topic, entity, or phrase group, it can be evaluated faster, and ranked better initially. Initial Ranking Algorithms decrease the cost, the time needed, and the computation needed for the search engines in the context of crawling, indexing, ranking, and serving.
An initial ranking algorithm can be supported by a re-ranking algorithm.
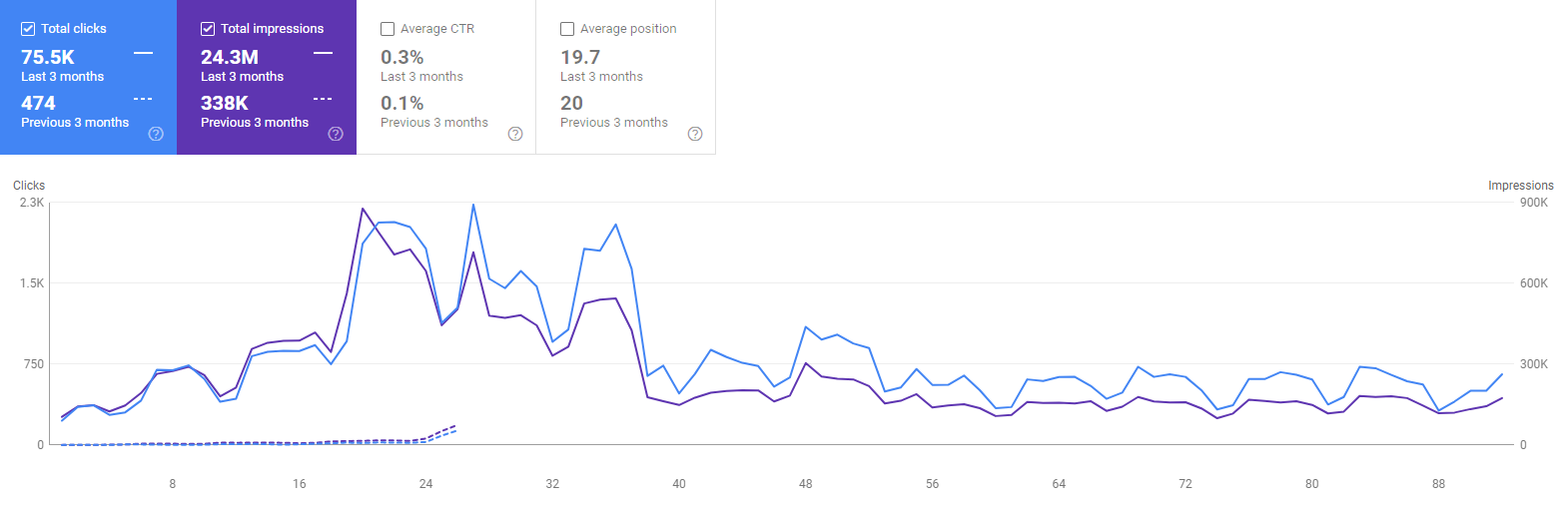
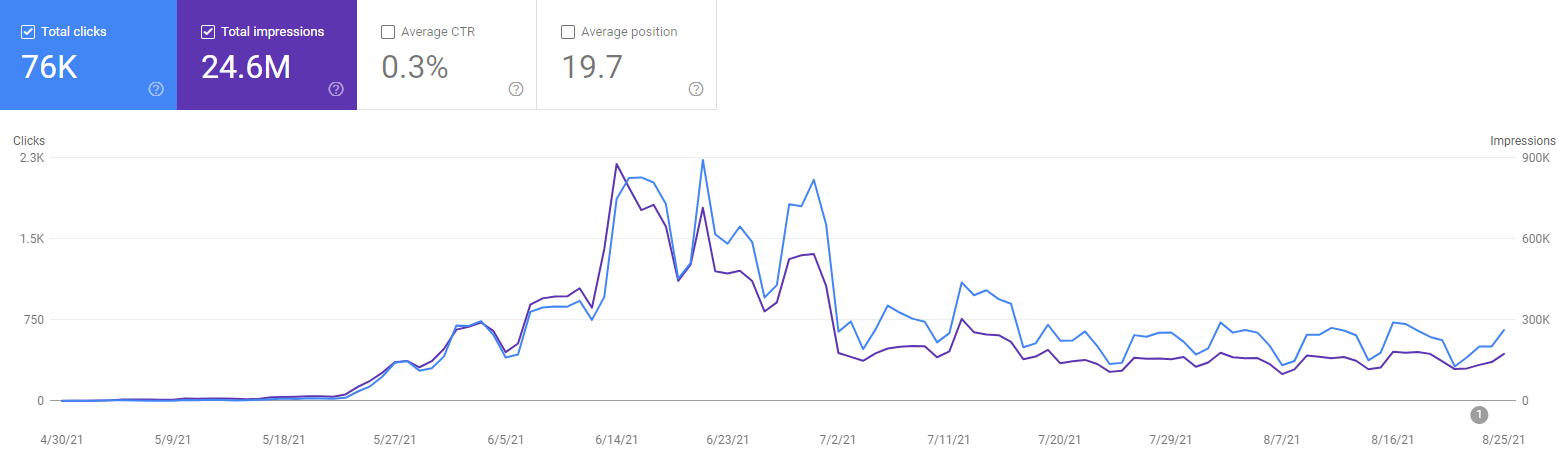


What is Re-ranking for SEO?
Re-ranking is the process of evaluating and modifying the initial rankings and existing rankings of a query result instance. A Search Engine Result Page includes the filtered web page documents for a specific query based on relevance, quality, reliability, authority, popularity, and originality. The re-ranking algorithm’s purpose is to support the initial rankings by increasing the efficiency, quality, and sustainability of the SERP with different SERP Features, and sources on the web.
Re-ranking algorithms for a search engine are crucial to continuing to satisfy the users’ possible and related search activities. Calculating the different search intent possibilities based on simple or complex user queries, and matching these search intents with different documents, requires different types of re-ranking algorithms. A Re-ranking process can be evaluated based on relevance, and another one can be evaluated based on the freshness of the document.
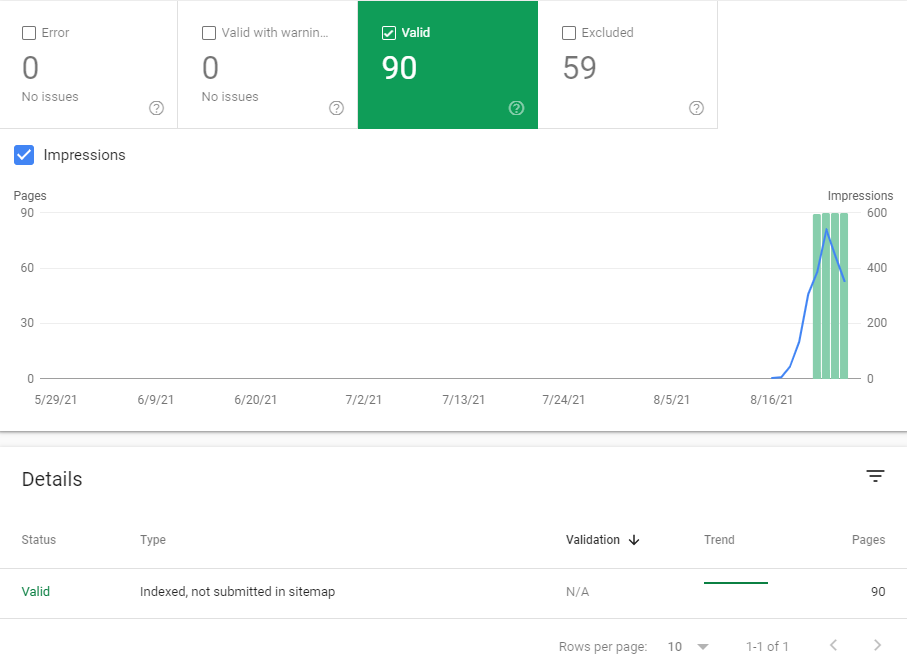
ForexRecommend, initial ranking, sitemap from robots.txt

Encazip, Authoritas URL-Link

BKMKitap.com Link
How Does Re-ranking Work in SEO?
When a web page is initially ranked, the re-ranking process starts after the first feedback from the web. The feedback from the web after the initial ranking process can be a timespan, user behavior, source changes, web page changes, external reference changes along with internal and external popularity signals. Re-ranking algorithms can be triggered to make a Search Engine reevaluate a web page so that the rankings can be changed.
How to Trigger a Re-ranking Process from Search Engines for SEO?
To trigger a re-ranking process, the web page document can have a new external reference, internal reference, or a content change. A re-ranking trigger can be acquired with controllable and uncontrollable factors for SEOs.
- Uncontrollable factors of re-ranking triggers for SEO are trending news, query demand changes, Search Engine Algorithm Updates, or bugs, and seasonal changes.
- Controllable factors of re-ranking triggers for SEO are external, and internal changes at the level of a website, web page, and intersection of external, internal, website, and web page areas. Such social media accounts of the brand are internal for the brand but external for the website in the context of SEO evaluation.
The next section of the article has many learnings from Dear Bill Slawski. As the biggest fan of Bill Slawski, I owe many things to him, especially my vision. Thus, we all should thank him for the vision and the inspiration that he gives.
Koray Tuğberk GÜBÜR
What are the Re-ranking Methods and Criteria of Search Engines?
The criteria and methods that can be used by a search engine for reranking the web page documents for user queries are listed below.
- Rerank search results by filtering duplicate, or near-duplicate content: A search engine can filter the duplicate content or highly similar content to the other instances without any additional value or prominent source attribute. Even if a copy or duplicate content is initially ranked, the specific content can be negatively re-ranked by the search engine based on other criteria.
- Rerank Search Results by removing multiple relevant pages from the same site: There are three different possible outcomes of multiple relevant pages for a specific query, one is cannibalization, one is being clustered for different subqueries, and one is outranking computation. If two web pages are closely related to a query, they can cannibalize each other and create ranking signal dilution. If two web pages are competing with each other for different attributes of the same entity by subqueries, they can support each other by being clustered. In the last option, the more relevant, externally, and internally popular one can outrank the second page to be reranked.
- Rerank search results based upon personal interests: Personalization of user, and user segments are closely related to the historical data of a web page, and the source. A search engine can track a user’s interests, and cluster the user with a user segment to modify the search results for better quality SERP instances. A search engine can rank a web page document for a user’s personal interests higher or lower than the usual. A query pattern, past search activity, and visited sites can affect the rankings on the SERP for individual users. These modified ranking results for personal interests can be used to modify the default SERP versions for specific trends, or SERP instances without any personal information.
- Rerank search results based upon local interconnectivity: Local interconnectivity between the web page documents includes the links between documents within a closely related web graph. If there are “n number of documents” for a query, if these documents mostly link certain sources, and if these referenced sources link some other sources, local interconnectivity for specific documents can be measured. Thus, the Programmable Search Engine of Google includes a parameter for retrieving documents if only they link a specific document for a query. To learn how to use the Custom Search Engine API of Google with Python, read the related guideline.
- Rerank search results by sorting for country-specific results: A user may want to see results only from a country-specific domain or country-specific IP. A topic or entity can be more popular for a specific country. In the field of SEO, from time to time, the IP Address of the source (website) can affect the local search rankings of a domain. If a domain has an IP Address from Poland or Australia, it can have higher rankings for the users from the specific country. Also, even if the IP Address is from some other country, if the source has lots of external link references from other countries, the Search Engine can relate the specific source for these localities, or countries again. In some cases, if the source has an extensive amount of content about a country, the Search Engine relates the source with that specific country for reranking processes.
- Rerank search results by sorting for language-specific results: A user’s operating system language, browser language, or communication language can affect the reranking process for specific queries. Query language, and preferred documents’ languages, can affect the reranking computation for a Search Engine. If a user is located within a multilingual country with a device with the local languages, the results can be mixed with the country-specific and language-specific results based on the query language. Authority for a topic and the initial-ranking potential of a source can help a website to rank higher across different languages and regions for different queries, devices, browsers, operating systems’s and user languages.
- Rerank search results by looking at the population or audience segmentation information: Audience Segmentation is the process of creating a demographic profile that includes gender, age, location, interest, income, occupation, character, and condition profile for the larger user segments. The first population assignment can be created with the first ranking score (initial ranking score) during the document retrieval process. When the document is retrieved, it will be matched with an audience, which is called the first population. This matching will generate a “selection score”. The same process will be performed for the second document too. After the second “selection score” is created, the second audience and the first audience will be compared to each other for creating a better-consolidated population and audience segmentation. When the audience profile is finalized, the selection scores for queries and documents will be refreshed, and the reranking process based on audience segmentation will be completed. During the audience segmentation for different documents for reranking by the Search Engine, historical data has been collected and used.
- Rerank search results based upon historical data: Historical data can be used to gather information across historical changes for a document. Historical data can define a document again based on historical changes for content, visual design, layout, brand entity, and external and internal popularity changes. A search-demand change or trending topic can change the historical importance and quality data of a document. When the historical data is used, an older document with a larger dataset for the successful click satisfaction feedback can have better rankings. Thus, historical data deficiency is one of the main disadvantages for the initial-ranking score of the new sources for a topic or entire web.

Systems and methods for modifying search results based on a user’s history
- Rerank search results based upon topic familiarity: Topic Familiarity refers to the expertise and detail level of the document, not the topical familiarity between different topics. A document can have more detail for a topic while another document might have a basic summary for the same topic. A Search Engine can understand the user’s preference, and rerank the documents on the SERP for satisfying the users’ document preferences. Writing style, opinions, design, source type, stop word count, and information count can be used to understand the document’s familiarity with the topic itself.
- Rerank search results by changing orders based upon commercial intent: According to the search intent, a search engine can change the order of the documents on the SERP. If a user explicitly states that the search intent has commercial characteristics, the search engine can change the SERP design, features, and preferred sources. One of the first examples of ‘commercial intent-based reranks’ was Yahoo’s Mindset.
- Reranking and removing results based upon mobile device friendliness: A search engine can use a Mobile-friendliness Indicator with mobile-friendliness indications to re-rank the URLs based on user agents. Usability of the web page is necessary to satisfy the need behind the query, and for certain user-agents, a search engine can re-rank a website overall, or a group of webpages, and individual webpages. According to the data, and implicit feedback from the web search engine users, a search engine can initially rank a website higher, and re-rank it for certain user agents and web user device types such as mobile phones, and tablets.
- Rerank search results based upon accessibility: Web accessibility is a user experience term that aims to improve the usability of websites for people with disabilities. Web accessibility is important for SEO since a certain amount of the intended audience of the source (website) has disabilities, making a website usable for everyone is an advantage to satisfy a broader audience on the web. Google has many “Voluntary Product Accessibility Templates”, and in Lighthouse, Google Developer Guidelines, PageSpeed Insights API, and their own Accessibility Guidelines they educate content publishers to make their websites friendly for everyone, including the ones with disabilities. A search engine can re-rank the sources on the web for different types of queries based on their accessibility, and friendliness for people with disabilities. If a website has color contrast issues or visual and non-visual communication issues for disabled people, a search engine can decrease the usability, and click satisfaction score of that specific website. Sundar Pichai, CEO of Google said many times “They build for everyone” by taking attention to the term web accessibility.
- Rerank search results based upon editorial content: A search engine can understand the theme of a query, and based on the theme of a query, editorial opinions, or editorial content can be favored on the web. Thus, having the correct content format, and tonality for a group of queries is important to take advantage of the re-ranking process, especially the editorial content. A query theme can be reflected on the verbs or the nouns, and entities within the query, based on the query theme, certain opinions, or certain sources can be favored, or not favored for being re-ranked by the search engine.
- Reranking based upon additional terms (boosting) and comparing text similarity: A search engine can re-rank the results based on text similarity to check whether the found documents are related to the specific query or group of queries. According to the research and patent of Query-Free News Search, Google can generate queries, match these queries to the portions of news articles, and check the similarity of articles to each other to filter out the irrelevant ones. In this context, text similarity can be an advantage to be ranked better during the re-rank process, but also being unique, comprehensive, and more informative can help to be seen as non-duplicate, and even the most authoritative source for the specific topic, and news for that topic. During the research paper, the A5-HIST and A4-COMP algorithms are used to generate queries from text segments to find the most relevant similar documents to be ranked together. A search engine can have obstacles in taking results for vague queries or being able to find similar documents for too specific queries, thus they also use A7-IDF and A6-3 algorithms to shorten the queries until they get a result. These details to find the text-similarity between news articles are important because it shows the obstacles of a search engine during the re-ranking process for a variety of queries, queries that are hard to satisfy, and newsworthy.
- Reordering based upon implicit feedback from user activities and click-throughs: Google and other search engines can use implicit user feedback and activity on the SERP, and in the web page documents to re-rank the sources on the query results. “Modifying search result ranking based on implicit user feedback and model of presentation bias” patent of Google, and “Query Chains: Learning to Rank from Implicit Feedback” research shows that instead of taking every user feedback into account, taking the implicit user feedback for longer timeline help to decrease the noise while increasing the efficiency. A search engine can understand the typos for queries such as in “Lexis Nexis” and “Lexis Nexus”, or it can use machine learning to evaluate the implicit user feedback. The good part of re-ranking with implicit user feedback for Search Engines is that it decreases the cost of the re-ranking process, and it is document-independent since it only focuses on the users’ behavior instead of the words on the documents. Thus, the relevance algorithms and implicit user-feedback algorithms support and complement each other to improve the efficiency of the re-ranking process.
- Reranking based upon community endorsement: Community endorsement, or social media shares, collaborative consistent web search behaviors can signal the popularity, reliability, and relevance of a source, or a web page of the source for a specific topic, trend, for a certain amount of time. Community endorsement can help a source to improve its prominence, search demand, and usability to the search engine. Click, selection, session ID, and statistical count of the number of times a page has been endorsed, bookmarked, shared, mentioned, or quoted. Community endorsement for re-ranking is also important to see the consistency and naturality of the external link-related references to a source, or a web page document. The link selection, or snippet selection without a “query term” and “terms from the document” matching can signal a synonym, and it can trigger synonym and query expansion algorithms. Thus, community endorsement can also affect the neighborhood SERP instances, and it can trigger a re-ranking process for these queries too.
- Reranking based upon information redundancy: Re-ranking query results based on information redundancy uses the “word distribution probability”, and “answer redundancy”. If the query breadth is narrow, and the query is vague, a search engine can try to understand the word distribution probability for possible and related search intents to re-rank the results to satisfy the search intent. The purpose of “reranking based upon information redundancy” is to decrease the number of off-topic documents and repetitive documents from the SERP for certain queries. Search engines rank 8-10 and in some cases with extra SERP Features 14-20 organic search results on one SERP instance. Thus, by re-ranking the documents on the SERP, it increases the total information redundancy that can be presented on a single SERP instance to improve the user satisfaction possibility. Information redundancy for documents can be acquired by calculating the word distribution possibility for every document. A result set and results from a result set can be compared to each other to improve the SERP’s information redundancy. Re-ranking based on information redundancy will improve the re-ranking process of multi-angled contents that cover multiple contextual layers for certain topics. For instance, “Abraham Lincoln Theme Park, Abraham Lincoln, and Assassination of Abraham Lincoln, Political Quotes of Abraham Lincoln, Personal Life of Abraham Lincoln” are different topics, and they will have different word distribution probabilities. According to the query, context of the query, and context of the user, the search engine will determine a different information redundancy value for all of these different but related topics.
- Reranking based upon storylines: A search engine can generate storylines from the results on the SERP. A storyline can summarize a result web page document for a query, and a storyline can summarize multiple web pages from the SERP at the same time. A storyline can be used to define the SERP documents thematically, and similar documents will generate different storylines, and be grouped together. The purpose of the reranking with storylines is to improve the quality of the SERP, and diversified result counts on the SERP. The global ranking mechanism of Google (PageRank) is to understand the important sources on the web that mentions a specific term, but it also doesn’t increase the quality of the second, third, or ninth page of the query results. There is no proper quality difference between the 11th-ranked document and the 44th-ranked document for a query. The re-ranking process based upon the storylines tries to improve the quality of SERP by decreasing the prominence of PageRank. Re-ranking based upon storylines can diversify the SERP with more relevant documents, “focused vocabulary” can be used to group pages, and co-occurrence possibilities can be used to see the context of the document. This method is not implemented as “storylines” but, search engines have used the re-ranking based upon relevance, and fact redundancy by extracting facts, prepositions from documents by calculating the importance score of the document for the given entities in terms of definition, and explanation.
- Reranking by looking at blogs, news, and web pages as an infectious disease: Turning search engine result pages’ documents into storylines via vocabularies, and co-occurrence probabilities, distribution and reranking documents on the SERP based on “blogs, news, web pages as an infectious disease” are related to each other. A search engine can see the most co-occurring terms together, and also it can recognize that some new terms and concepts started to co-occur together in certain types of documents, and sources within a certain amount of time. These co-occurrence changes can be used to detect the newsworthy queries, and trending terms in the context of search demand. And, a search engine can group different sources with different sources as storylines, or it can individually re-rank them based on the newsworthiness of the source for a possibly trending search query.
- Reranking based upon conceptually related information including time-based and use-based factors: A search engine can group the documents based on co-occurring terms. And, it can re-rank by re-grouping them based on user affinity, or the user segment. The user segment’s interaction, users’ location, and users’ selection change, based on selection change, if the co-occurrent terms change also, the search engine can refresh its grouping choice while re-ranking the search engine result page documents.
- Blended and Universal Search: Blended Search is the unofficial name of Universal Search. Blended Search or Universal Search is the name of mixing images, podcasts, movies, videos, news, dictionaries, questions, answers, knowledge panels, and other types of search engine result types into the regular blue link results. Blended Search or Universal search can change the order of the results, and it can push some of the results into the second page. Also, Universal Search can affect the ranking of the documents, since some of the documents will have a better relevance for image search, the universal search can boost the document if the images are also important for the specific query group. In this context, the universal search can affect the ranking of the results, and re-rank them based on the feedback from the users for different search verticals.
- Phrase-Based Indexing: A search engine can differentiate the bad phrases and good phrases from each other. Unknown entities, topics, or queries can be detected by the search engine if only they make a “good phrase” sample. A search engine can expand its knowledge base, and fact repository based on new good phrases, thus having a good phrase threshold is important to keep the knowledge base, and fact repository clean, and efficient. In this context, a search engine can group phrases, and check their co-occurrence frequency to re-rank the search engine result pages. From spam detection to the phrase taxonomy creation, or understanding the query breadth, phrase-based indexing is one of the most fundamental perspectives to keep SERP quality high. In the context of re-ranking the query results, good phrases, phrases from top-ranking results, phrases from authoritative sources, and phrases from side contexts can help a search engine understand the users, and documents around queries in a better way.
- Time-Based Data and Query Log Statistics: A search engine can change the look of the universally created SERP instance, and it can change or re-rank the documents on the SERP. A query can have a different meaning, and query intent from morning to night, or from winter to spring. In this context, the search engines can understand the meanings of the query, and user affinities in a better way to rank these documents in a better methodology.
- Navigational Queries: A search engine can understand the queries with only a navigation purpose to a specific web page. Subsequent click count, click reversion, mouse-over, and result selection time can be used to see whether there is a navigational character in the query or not. Query logs include a query, a search activity, and a selection activity that signal a query’s purpose, and the satisfaction of the click. If the users click only a single result, and if the document includes a brand, location, or any kind of name entity within the prominent relevance points, the query can be chosen as navigational for the specific document. A navigational query detection system can re-rank the documents, but also it can re-rank the non-navigational documents. If a source is chosen by the search engine, the other sources can be re-ranked according to the similarity, relevance, or closeness to the specific source in the context of the navigational query. Thus, for affiliate industries, or aggregators, still creating landing pages, useful information, and definitive documents for the brands or institutions based on navigational queries will improve the relevance of the source to the specific topic, and it will strengthen the historical data with the targeted user segment.
- Patterns in Click and Query Logs: a query log includes a search term and the document retrieved from the ordered index of a search engine. A click log includes the click event for the selection of a document. If the people that search for a query, also search for other queries in a sequence, these queries will be named sequential queries. And, if the sequential queries do not include the same terms, or same entities, or an entity from the same type, it doesn’t mean that they are necessarily relevant to each other. A search engine can cluster the queries based on their chronological order for a search behavior pattern, and the documents that are selected for certain types of questions, entity types, or attributes can be ranked higher. The search engine can recognize the context of the search session based on sequential queries. A sequential query can have a query path based on the queries that are used. For instance, if the searcher used the terms “banana”, “apple”, or “berries”, the query path will be “banana/apple/berries”. Different permutations can affect the ranking of the documents. The search engines can determine “content terminuses” based on different query paths. And, these content terminuses can be changed based on the searched query paths. A pattern can benefit a source if the source includes all the relevant and distinctive seed queries with different content items. In this context, patterns in click and query logs are also related to the topical authority. Based on different query paths, and search behaviors search engines will adjust a “proportional relation to the likelihood” for relevance, and the context of the search behavior. In terms of re-ranking of a search engine result page documents for a query, and the possible search intents, the query logs, click logs, query patterns, content terminuses, and content items can be used.
- TrustRank: TrustRank is a term that belongs to Yahoo initially, but the Google search engine also used it within its patents. In the context of re-ranking the search results, a search engine can use trust signals. The main theme of TrustRank is the process of understanding the trust signals for a source, web entity, or document owner based on links, or the people’s labels for them. Since both of the search engines (Yahoo and Google) used the term TrustRank, it also shows the significance of having search technology patents. And, thus Google didn’t focus on links for the TrustRank patent, because Yahoo did it instead of Google. TrustRank Perspective of Google relies on feedback from the people on the web for a web page. And, in this context, in 2009, Google published Sidewiki. Sidewiki was a system where people can state their opinions on a web page, and it was working as an extension for browsers. Also, Local Experts for Google Local Search, Inferred Links, mentions, reviews on the web, social shares, and community proof for a web page can affect a website’s, and the web page document’s TrustRank. Google’s TrustRank understanding is highly similar to the content distribution system of social search engines such as Facebook, TikTok, Instagram, or Twitter. If the web page has good feedback, and if it is labeled in a good way, the web page will have a better TrustRank. On the other hand, Yahoo’s TrustRank understanding relies on links. Thus, it is called a “Link-based spam detection system”. According to Yahoo, TrustRank is a link analysis technique related to PageRank. Basically, it uses the high authority pages to determine other high authority pages while recognizing the reciprocal links between different websites. Besides the TrustRank understanding of Google, and Yahoo, there are more methods, and patents from search engines that focus on trust signals whether it is from social activity or links. Thus, the TrustRank term has better prominence, because it focuses on the basics of trust signals such as “annotations for a page”, “labels for a section of a web page”, or “highly authoritative link for a web page”, and “size of a web page link farm”. In the context of re-ranking documents based on context and trust, the TrustRank is a useful and evergreen understanding for search engines.
- Social and Community Evidence for Quality: Social and Community Evidence for a web page to be shared, or interpreted shows how the web page content is prominent in a specific country and the industry. Social and Community Evidence can be followed on the Search Engine’s technology designs, or some of the official explanations along with the search engine result page feature from the SERP for social media. Social and Community Evidence is prominent for being ranked or re-ranked in the future.
- Customization based upon previous related queries: Customization based upon previous related queries is a method for re-ranking the search engine result pages based on query logs. If two queries are related to each other, and they are sequential, based on the following queries they can change the search engine result pages, just for that query log. The difference between customization based upon previous related queries and the “Patterns in Click and Query Logs” is one of them affects the conditional search engine query results, and the other one affects the universal search results by re-ranking. Based on this, if the query includes a region or a language signal, it can customize the ranking by re-ranking. If a source is more relevant to the specific region, or district, it can overrank others due to the query’s regional signals rather than just simple string matching. In this context, the misspelling queries, correlated user behavior in a short period of time, lexical relations such as synonym, antonym, acronym,

Various methods for ranking and re-ranking can be seen above. The initial ranking score definition and function can be checked below.

Customization based upon the previous related query reranking methodology can generate different relevance and ranking scores for different documents for different related queries. For instance, a web page can be more relevant for the first query, and the competing document can be more relevant for the second query. And, if the user searches for the first query, and if it chooses the first document, the competing document might not have the same weight as the second document in the context of ranking score calculation, and re-ranking.
- Being linked to by Blogs: A search engine can weigh some links on the web more than other links based on the type of source. A search engine can weigh different types of links from different types of sources based on the purpose, and the type of the query. Being linked to blogs, patents, and methodology belong to Microsoft. And, it is about differentiating links from each other. In this context, Microsoft thinks in the “Ranking Method Using Hyperlinks in Blogs” patent that being linked to blogs is valuable, and they can pass more PageRank. Because of this understanding, in the golden age of Black Hat SEO, the tier 1, tier 2, or tier 3 blogs, web 2.0 links, and Private Blog Networks, link farms were popular. Over time, the search engines decreased the value of links from blogs unless the blog doesn’t provide real value. This patent sample is from 2007, and in 2007 the blogs were also in trend. In this context, you can assume that the re-ranking methods of search engines and the re-ranking information points can change their prominence or importance over time. Another important statement from the same patent is that Microsoft classifies the ranking algorithms of the search engines as “content-based”, “usage-based”, and “link-based”. And, when it comes to relevance, we also have “query-dependent” and “query-independent” relevance points. And, this methodology is a “query-independent”, “link-based” re-ranking algorithm. In this context, the Search Engine tries to find some better ways against the spammy endorsed pages, and it mentions the “Systems And Methods For Ranking Documents Based Upon Structurally Interrelated Information” patent. Based on the “Structured Interrelated Information” understanding, it also modifies the PageRank calculation to give more weight to the non-endorsed, and informative links from blogs.
- By Ages of Linking Domains: The domain age is a controversial topic when it comes to SEO. By Ages of Linking Domains is another method of re-ranking for search engines, and it is related to the terms Google Sandbox, Domain Maturity, Expired Domain, Linkage, Link Echo, and Ghost Links. If a backlink is removed from a web page to another page, the PageRank decrease can cause a re-rank. If the link gets older, and if the link source domain is more mature, it can cause more PageRank increases by changing the re-ranking process of search engines. Based on the domain age, we can tell that the domain age is actually an important source for historical data, selection scores from queries, and consistency-trust signals for the industry, and the users. But, this situation caused “Fear, Uncertainty, and Doubt (FUD)” as a sale tactic for domain registrations. And, since it has been exploited by domain registrars, Google repeatedly said that domain age is not a factor for ranking. In this context, we can tell that a link that lives longer with more consistency is better than a temporary and inconsistent link. Search engines try to find consistency over time for different ranking signals. In the “Ranking Domains Using Domain Maturity” method of Microsoft, different methods for the domain age are mentioned, such as registration date, the time that the domain is linked the first time, or it is crawled the first time. To give a link weight based on the domain maturity, the search engine mentions the “contributing domain” definition. Based on that, it is not just about maturity, but also contribution, and the value of the domain.
- Diversification of Search Results: Diversification of search results is related to the Information Foraging Theory and web search engine users’ behaviors on the SERP. A search engine can show different types of documents, or SERP features on the SERP to direct the users to certain types of documents, or search behaviors. Diversification of search results is closely related to the search intent distribution, and search activity coverage, along with the connection of concepts, and interest areas. In the Search Off the Record Podcast series of Google, Garry Illyes talks about “Universal Search” in the “Cheese, Web Workers, universal search, and more!” episode. Google can show different types of search features within a bidding system by measuring the implicit user feedback and its cumulative characteristics based on historical data. The search vertical icons below the search bar such as “image”, “video”, “news”, “shopping”, “flight”, and “books” can switch places, and order based on the dominant search intent, and search features. According to the search features, a search engine can differentiate its re-ranking algorithms. If the images on the SERP take engagement, or if it satisfies the users, image-landing page pairs can be used for the re-ranking process. Thus, while creating a web page for a probabilistic search engine, SEO should create a universal web page for every format of the content, by covering every contextual layer. Diversification of search results can happen with different methods in the context of re-ranking. For instance, a search engine can diversify search results based on fresh queries, documents, personalization, past queries, and the location of the user. Every query that is put into the search bar has an ambiguous nature, and search results diversification is closely related to satisfying all the possible search intents with different content formats.

Deduplication, and canonicalization, along with cannibalization, are also related to the Search Engine Results Page Diversification. A search engine might re-rank the results if a source (web entity, domain) has multiple results within the SERP for a query. A search engine might choose one of the competing web pages to outrank another one, or it can cluster similar ones with a different SERP design, such as “site-links”, or “one hat site-wide links”.
In the context of SERP Diversification, a search engine can use “non-diversified”, “diversified” systems, “aspectual tasks”, and “ad-hoc tasks” to test the users and their comparison in terms of “engagement stop-time” to the users.
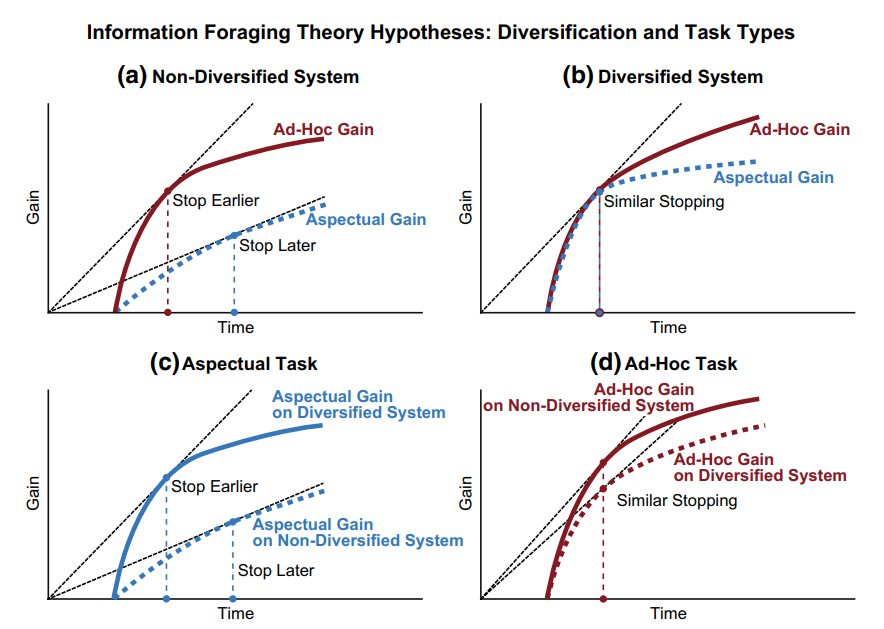
In the figure above, the “a”, “b”, “c”, and “d” sub-figures compare the “stopping time of engagement” based on different Diversification of Search Results profiles. And, in the context of result diversification, it appears that complex search tasks require multiple queries, and if the results are not diversified, it ends up with multiple search behaviors.

In the context of search results diversification, Google has started to use “Dynamic Content” as below.

For a prominent and complex entity, if it overcomes the threshold of the “multi-faceted search behavior” count, it starts to use dynamic search features by multi-facets. It uses “videos”, “top stories”, “people also ask”, “knowledge panel”, “knowledge panel expandable questions”, “images”, “people also search for”, “suggested search queries”, and “blue links”, “see results about”, “local search pack”, “electric animals-industry” as related “entity types”.
The search results diversification as a re-ranking system, information foraging theory, and the “degraded relevance ranking”, or “relevance degradation” are connected. These terms are connected to the “search activity coverage”, and “search intent understanding” via sequential queries, query paths, and chained search behaviors. Prabhakar Raghavan (Vice President of Organic Search in Google) also has nice research on this topic.
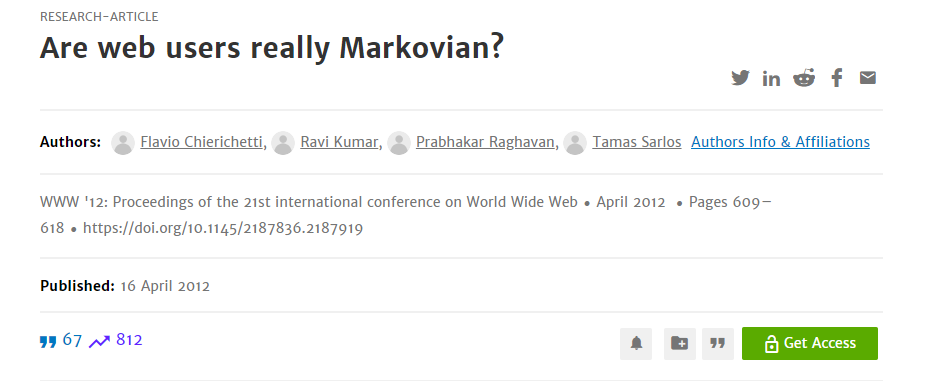
“Are web users really Markovian” research paper tries to find some relations between the chained search activities. The latest MuM and LamDA announcements of Google during the Google IO 2021 are also connected to the “search activity coverage and relation”. In the context of re-ranking search results, a search engine can understand different contextual layers of a topic, related entities, their connections, and similarities, and a complex search task can be perceived. If the topic exceeds the threshold of complexity and prominence, you will see a “search result diversification”, or “dynamic content” on the SERP.

The source that covers all of the related contextual layers initially will have a better initial ranking for the specific topic. And as the topical coverage increases, the topical authority of the source during the re-ranking process will be increased too.

Above, you can see how a search engine can predict the possible behaviors of users. Below, you can see an example of the SERP design for ad-hoc retrieval.

This section is detailed purposely in the context of user and search engine communication method explanation.
- Desktop Search Influenced by the Contents of an Active Window: A search engine can re-rank the documents on the SERP based on the applications, or the programs that are used, and is used during the search activity or before the search activity. The context-sensitive ranking has three sections, user, device, and search contexts. In this perspective, a search engine can relate the device’s context to the users’ true search intent for a specific moment. A computer can open multiple user interfaces at the same time, and these activities and inactive user interfaces might not be related to each other. Or, they can have a sequential contextual relevance with each other. Thus, a search engine can recommend new content, or it can rewrite the query of the user to relate the documents or content from the inactive user interface to the new search activity. Using desktop search influenced by contents of an active window, or “Systems and methods for associating a keyword with a user interface area” is connected to the inactive browser tabs or inactive programs, and web applications in the background. Unifying different platforms, and activities of users to the search results with re-ranking can be observed while YouTube shows the search results from Google. Or, when a user watches a movie on Netflix, and he/she starts to see related videos on YouTube. The same situation can happen when a user opens a browser tab with the title of “World of Warcraft”, and when he/she types “world” in the search bar, a search engine can choose “Blizzard” related queries instead of “world news”. Some of these

According to the “Systems and methods for associating a keyword with a user interface area”, search engines can choose only one result among others from the “re-written implicit query”. And, search engines can give more weight to the related queries to the “re-written implicit query”. A search engine can also use the time periods between the active, and inactive user interfaces, or the media that is plugged into the device such as a microphone, CD, DVD, and more.
- Expanded and Adjacent Queries from User Logs: Query Processing is a part of the relevant understanding between documents, and queries. A search engine can re-rank a document based on the query term match, or terms from the query, and their proximity to each other within the document. The query log includes a query input and a SERP behavior instance. A query can be clustered with other queries if the query is searched just after other queries. “Re-ranking search results based on query log” is a patent belonging to Google. Its methodology is basic and fundamental. The “adjacent queries”, or “sequential queries” can be used to understand relevant queries, and if a query is more related to the other query, the rankings can change since the possible search activities will change. Thus, creating correct contextual vectors, and understanding the contextual domains are important. There are some essential terms from the patent such as “lexical similarity measure”, “frequency of query”, “query utilization”, “initial query”, “temporally related query”, “lexically related query” and “language model”. Lexically related queries are the query terms that are related to meanings, and temporally related queries might include trends or small contextual bridges between them. The frequency of a query can trigger query utilization via an iterative re-ranking process to understand which query is related to which context, and how other queries can possibly be searched at the same time. This patent is closely similar to the Google Search Engine’s Multi-stage Query Processing methodology which is refreshed over years, along with Phrase-based Indexing methodologies. Simply put, a search engine can change the context of a query by classifying it with others based on frequency, lexical, trending behaviors, and query logs. Query classification can affect the rankings, and trigger a re-reranking process. Thus, creating comprehensive sources by including all possible queries and the need behind the queries is a must from an advanced SEO perspective.

- Social Network Endorsements: A search engine can re-rank the documents on the query results based on the engagement rate of a document on social media. Re-ranking search results based on social media and social endorsement is also related to entity-oriented search and SEO. Entity-oriented search understanding means that a website can have a Facebook page, or YouTube channel, and lots of different influencers, and authors; all these attributes of the website will be united under one “web entity” to evaluate the quality, trust, and expertise signals. In this context, between 2010-2015, Facebook likes, and shares affected Google’s SERP heavily. The main reason Google was being influenced by search engines is that Facebook was too popular, and it was one of its main competitors of Google. Google has created Google Discover or “queryless search feed” by being inspired by Facebook, and it has tried to create its own social media platform such as “Google +”. In the TrustRank section of this guide of search engine re-ranking systems, we also have seen that they created “Sidewiki”, and Google has many other patents when it comes to Social Media Understanding, and tracking. Google can show the social media profiles in the Knowledge Panels, it can be used to understand an entity better, and hype on the social media platforms for a hashtag, or a topic, an account can trigger news-related SERP features for a topic, or it can make Google use the specific content on the Google Discover. We also know that Google Discover bots use “Open Graph tags’ ‘ when they find useful information, and they check the consistency of Open Graph Tags and the SEO-related HTML tags to improve the confidence score.

Above, you will see a post from 2011 that has been written by Matthew Peters. And, below you will see a correlation plot between the Facebook shares, along with other engagement types, and the Google Rankings.

If you look at the past of SEO, you will see lots of similar search results, proofs, or explanations from Forums and Search Engines themselves.

During the same period, Google started to demote Facebook Videos, and it promoted YouTube. Google also started to decrease the traffic of Facebook from organic search, and it has started to use Facebook only for cooperation pages, and personal profile listing results mostly, along with some “#”, hashtag-related results. Besides the feedback from Social Media platforms, it is true that Google can use Social Media activity to understand the queries or the context of the search. It can signal the trust or the brand power of a web entity, and we know that Google has systems to score influencers, or it has systems to aggregate text items, and feedback from social media platforms based on consistent user feedback. The patent “Methods, systems, and media for presenting recommended content based on social cues” also tries to find contextual relevance based on the social connections, these connections do not have to be in social media platforms, but a search engine can use social media platforms and their media to see these social connections.

Lastly, an “Automated agent for social media systems” can be used to measure the users’ behaviors and connect multiple social media profiles to each other.

In this context, social media endorsement or any kind of endorsement, and mention can be used to re-rank search results by search engines. An endorsement can show trust and quality, or it can show the untrustworthy, and non-quality sides of an entity to the open web. Thus, we also know that search engines started to list LinkedIn profiles of employees of companies within PAA questions, or it directly shows events and trust-related information to the users from their own social media platforms.
- Personalized Anchor Text Relevance: Anchor texts can signal the relevance and quality of a web page. In some situations, it can also signal irrelevance or non-quality. Thus, the surrounding text, or the annotation text, and inferred links, mentions, and language understanding are important for anchor texts. When it comes to SEO, there are different types of anchor texts such as exact match anchor texts, generic anchor texts, descriptive anchor texts, and more. And, in the context of the re-ranking process, semantic annotations, and semantic labels can be used to understand the anchor text of a document. Based on personalization, a search engine can weigh some anchor texts more than others, and it can re-rank the search engine result pages’ documents. These re-ranking processes can affect only the users that are the SERP personalized. A search engine can understand a web search engine user’s interest area by checking it past queries, consistent queries, address bar autocomplete options, and bookmarked URLs, or the user can explicitly state it to the search engine. In this context, anchor texts can carry different weights for re-ranking. If this is a general search behavior, the query logs, and the query processing can turn the individual SERP instances into the general samples of re-rankings.

One of the important terms from the “personalized anchor text methodology” is “personalized page importance score”. A web page can be more significant for a web search engine user based on anchor text-related signals. These anchor text-related personalization signals can include localization or topic-related filtering for query terms.

Personalized Anchor Text weighting can be seen as a “link-related re-ranking algorithm based on personalization”. A locale name, a topic-related name, a celebrity name, a power word, or statistics can trigger a better page importance score. In this context, creating multi-faceted anchor texts, and covering all possible segments of the intended audience within different search-related dimensions can be seen as the main methodology.
- Recognizing Semantically Meaningful Compounds: “Identification of semantic units from within a search query” is a methodology to find semantically related n-grams to each other, and match them to the relevant documents. A semantic unit locator can parse terms within a query, and it can generate different types of search results for each of these semantically related units. All the units can be tested for relevance for all the queries, and parsed sections of the query to see the overall relevance of the document. After processing the query, different combinations of semantic units can be generated, all these generated semantic unit combinations can be joined together for the overall relevance calculation process. Thus, a source should include all the relevant entities or entities from a query with all possible attributes based on the context of the source, and the main search intent for the overall site to become a topical authority. Query breadth and semantically meaningful compounds are connected to each other as well as substitute queries, synonyms, and lexical relations between words.

A section based on the “query breadth” and “semantic compounds” can be found in the image above which is directly from the related document. During the re-ranking process based on the semantically related compounds, a ranking component and semantic unit locator work together. And, the terms from the query are used for filtering the documents. In some aspects, the same method can be used for generating substrings from the parsed query terms, or using their synonyms, and lemmatized, variegated versions. Thus, making an author write with variegated phrases, synonyms, and lemmatization is also important as well as thinking about semantic closeness, and word proximity.
- Use of Trends and Bursty Topics: A search engine can re-rank documents based on whether they include trending topics or queries within them or not. If a document is closely related to a trending topic, and an entity, but if it doesn’t have the trending queries within it, the re-ranking process can promote the document with a weaker boost. In some examples, a search engine can boost rankings of documents, or sources, if they have related queries and entities for the trending queries and topics. The freshness of the document is an advantage for taking advantage of the “bursty topics”, and when it comes to the re-ranking or even the “initial ranking”, the query templates, and the document templates, along with the topical coverage are more and more important. All these aspects can be used to take advantage of the trending topics by improving the confidence score of the search engine for the benefit of the web entity. Antonio Gulli, the inventor of the System and method for monitoring the evolution over time of temporal content, explains the importance of the temporal trends to see the effect of newsworthy content on click satisfaction. In the system design of Antonio Gulli, there is a trend analyzer and also an entity extractor. The entity extractor handles the named entity recognition, and the trend analyzer takes the related queries for the entity, whether they are old or new, to check the trend-search demand changes. If there are too many new documents for a specific entity, the search engine can expect a trend change for the related queries. And, if the queries are from different IP addresses, a search engine can use a trend analyzer, and a clustering unit for the queries, and the documents. The re-ranking happens if there is a big search demand suddenly, or there is a big document publication suddenly. In this context, a search engine can prioritize some sources, if they are authoritative enough for the related entity. Thus, semantic SEO and News SEO are connected to each other. But, to use the trending topics for entity-oriented search in the context of re-ranking, an SEO can use the trend-worthy queries, and questions, answers, historical data within the content. Or, SEO Project’s digital PR and Social Media management parts can handle the trend-worthy topics. One of the important notes from this method is that if the fresh and sudden search-demand increases, the re-ranking process, and the boost that has been created can be delayed, or it can lose its effectiveness. But, since the historical data has been gathered, it can be used for the evaluation of the source for the specific types of queries, and the entities to support its authority.
- User Distributed Search Results: This methodology and the Custom Search Engine API, or the Programmable Search Engine of Google can be associated. According to the “User Distributed Search Results”, a search engine can re-rank the results of a query based on the reputation of the one who inserts the Google SERP for a query into his/her blog, or instant messages and emails. The programmable search engine gives the possibility for people to create a customized Google Search Engine experience. Below, there will be an example from the SEORoundTable of Barry Schwartz as an image.

If you use the “Custom Search” option above, it will mean that you will have an “inserted Google Search Results” from the website of SEORoundTable as below.
You might wonder why Google has created such a design, but in the old times, Google didn’t have its own browser which is Google Chrome, and it had only a toolbar which was Google Toolbar. Making Google more prominent, and visible on the SERP, was not easy. And, to generate a reputation score for the Google SERP inserter his/her own blog can be used for making Google more popular over the web. One of the other important things here is that the search engine talks about entity recognition even if the date is 2003.
The entity extraction here is important not just because of the timing, but also because it includes commercial purposes. Because an entity can be a product or a service provider. Below, you will find two different samples directly from the search engine.

[0029] FIGS. 1A-1C are diagrams providing a conceptual overview of concepts described herein. In this example, assume that a user (“Arthur”) is responding to an email from a friend (“Mark”) requesting information about a camera lens. FIG. 1A is a diagram illustrating an exemplary email 110 in which Arthur responds with a short text message informing Mark that the lens he was telling Mark about is the “100 mm F 2.8.” Email 110 exemplifies a typical user email responding to a question. FIG. 1B is a diagram illustrating another exemplary email, labeled as email 120, in which Arthur responds with the same message informing Mark of the lens about which he was telling Mark. Additionally, in email 120, Arthur pastes a link 125 into email 120 that references a review of the lens. As can be seen, by the text of link 125, link 125 is a textually long link that contains a number of terms that convey little information and are probably meaningless to Mark. Email 120 exemplifies another typical user email responding to a question.
[0030] FIG. 1C is a diagram illustrating an exemplary email 130 in which Arthur responds to Mark’s email using tools described herein. In contrast to emails 110 and 120, email 130 may include, in addition to the same textual response 135 from Arthur to Mark, a number of links and/or content 140 that were inserted by Arthur when creating the email. Links/content 140 may be information that was automatically generated by the email program used by Arthur in response to Arthur entering a search query such as “Canon100 mm macro lens.” As shown, links/content 140 include two images 141, two links 142 returned from a general web search engine, an advertisement 143 returned from an advertisement search engine, and a link 144 to a local company that was generated in response to a search performed by a local search engine. Arthur may have chosen to use each of the links/content 140 by, for example, a single mouse click on a graphical button associated with each of the results of the search query.
Within an email, with “advertisements” and “organic search results”, search engine results can be inserted into emails, instant messages, or a blog. In some experiments, a search engine can recognize the words within a message, and it can trigger itself with the related information, and re-ranked documents. But, since this is an early-time Google Patent, I care about this to see Google’s Brain Team’s vision.

Google can implement the different methods for the same problems, and when the technology grows for the same purposes, the same methods can be faster and cheaper. But, it shows what type of information they can use, and where they can use it. In this context, Google wants to exist within blogs, emails, and messages. It wants to track users for personal emails, or messages, and it wants to show relevant information and advertisements for all these places. It tries to present a “reputation for the users” and this reputation can affect the rankings overall. In this context, Google has done the things below to achieve the same results with different methods.
- Google has started to use Google Lens for product recognition, showing its prices, and other related products.
- Google has started to use Google Display Network Ads to exist within blogs with advertisements.
- Google has launched the Custom Search Engine, and the Programmable Search Engine.
- Google has started to track even ambient noise or background music, and search behaviors to suggest related products, and services.
- Google has used search personalization for re-ranking to understand the users’ context by checking their open, active, and in-active user interfaces, applications, and localization.
- Google started to check people’s last bought products, products on checkout, shopping history, last called numbers, or even the last visited places, working and commuting hours, and more.
- Google has started to show ads within Gmail.
- Google started to use Google Assistant for giving search results for messages, and conversations.
The things above can be understood via the “Contextual Search” article, and SEO Case Study better. In this context, I recommend you check the images below.

This is a sample of “Auto-generated results” based on the topic of an email. And, it includes a product such as a camera. The results are clustered as image and web results with similar names to today. Based on the implicit user feedback from multiple places, whether it is an email or social media platform, the search engine can re-rank the results.

The sample above shows a restaurant. And, it also uses the “localization signals”. Below, you will see another sample.

This sample is from instant messaging. Today, Google uses the same system for understanding the users’ interests, or their purchasing possibilities to improve the conversions of the ad. In the context of re-ranking search results, if someone gives certain products, sources, or web pages more weight, the search engine can give it more reputation.
[0094] The user selection of search results when creating content may provide an indication that the selected search results are relevant to the search query. For example, the search results selected by a user may be used as part of a reputation network. In general, a reputation network in some way quantifies the reputation or score of users as to their expertise in certain categories or topics. In the context of UDS, if a particular user incorporates many search results into content and the search results are frequently selected by readers of the content, this may be an indication that the user is an “expert” in the topic relating to the content, and his reputation score for the topic may be increased. This application may be particularly relevant to content applications such as message boards, where the message boards are typically categorized by topic.
[0095] More generally, regarding reputation, the gesture of selecting a result may be fed back into the system to impact, for example, raw result ranking, the raw value of an advertisement, raw reputation of a user performing a selection, or raw reputation of an application using UDS. These raw reputation results can be used, for example, to modify a document or advertisement ranking used by the underlying search engines.
[0096] Advertisements presented through UDS may, in particular, represent advertisements that have a higher likelihood of click-through and may therefore be more valuable to the advertiser. These advertisements may, for example, cost more than or be provided on different terms than other advertisements. In some implementations, the revenue or other benefit derived from advertisements selected by the content creator may be in some way shared with the content creator. In some situations, the fact that an advertisement is selected by an end-user may be used in some way to modify the reputation of the content creator that selected the advertisement.
And, we also know that the Custom Search Engines share the advertisement revenue with the owner and the publisher of the CSE, as told in the patent. And, when it comes to the re-ranking, if certain products have better feedback from the distributed search results via emails, blogs, or instant messages, the reputation of the product, entity, or service will be improved which is quite a similar methodology as in the social endorsement, Sidewiki, or Trust Rank generally. As I said before, same purpose, different methods, and technology…
“In another possible implementation, the search results may be refined based on information relating to the user of content creation application 218/235 or based on information relating to the intended recipients of the content. As an example of this, consider a profile created by or for the user that includes areas of interest of the user. The profile may be used as a basis to re-rank the search results. In other possible implementations, other information, such as, for a message board post, geographic information that is relevant to the message board post, may be used to refine the search results.”
Lastly, in the context of the re-ranking, search engines also state that all the search results can be evaluated based on the context of the web page, blog page, or emails and instant messages. Thus, search engines also plan to collect context data and SERP behavior data to refine and re-rank the search results.
- Advanced Search Users: To re-rank the search results, a search engine can focus on only a certain segment of the users’ search behaviors. In this example, Microsoft tries to focus on only the advanced search users or the users who use advanced search behaviors, patterns, and features to find the information they need via web search engines. The patent “Investigating the Querying and Browsing Behavior of Advanced Search Engine Users” shows information retrieval, and its hard sides and fundamentals. It mentions Google, Yahoo, and also the search operators such as question marks, plus, and minus. In this context, a search engine can focus on the queries that show complexity along with advanced search behaviors. This specific patent and the research behind it show what kind of dimensions can be used to measure and weigh a session in terms of characteristics. Below, you can see two different samples.

Queries that are used per second, query repeat rate, query word length, queries per day, avg. click position, click probability, avg. seconds to click are some of the metrics that can be used for re-ranking the results based on the advanced searchers. Below, there will be a second example.

The terms above can be used to understand the relevance of the document to the query based on the users’ behaviors for different SERP results. And, based on the behaviors, some of the relevant judgment assessments can change as below.

It shows which pages will get what type of relevance based on the behaviors of the users. Below, you will be able to see the relevance of these metrics to each other.

It shows the behaviors of the users who use the advanced search behaviors, and this patent and research paper was necessary to see how Information Retrieval can be improved. Since most web search engines do not use advanced search features, a search engine can try to choose only a certain group of searchers based on their search experiences to see the quality and relevance of the documents.
I usually call this “audience segmentation” which Google does to understand the categorical quality and context of a topic, but in the context of “advanced search users”, a search engine can re-rank search results based on the searcher’s search talents. In the context of search engine optimization, an SEO can use the Advanced Search of Google to see how the rankings change based on different filters, and dimensions, so that the optimization possibilities can be seen.
- Web Traffic: Web traffic, popularity or the mention velocity, selection over time, and other types of brand power signals, or website trust signals can be used to re-rank the web pages. In some practices, Google tries to merge the PageRank and the Web Traffic of a web page. The argument behind this practice is that Google thinks some pages have high page rank, but they do not have actual traffic, and some pages have high web traffic, but they do not have any page rank. For instance, on the web, most people won’t link to a porn website, thus a porn website won’t have a high page rank, but it will have high traffic. Thus, low PageRank can’t mean that the web page is not quality, or authoritative. In this context, a search engine will need to try to see whether a website has actual traffic or not. In this context, diversification of the audience, and traffic sources are also important. If a source has traffic from other sources rather than Google, or another search engine, it means that the source has value for the web users, and the search engine might need to re-evaluate its algorithm’s judgment for the previous ranking process. And, a web traffic increase and web traffic diversification can cause a re-ranking process.

Below, you will see a patent from Google which is “Sampling internet user traffic to improve search results”. It has the same purpose with a different methodology with Rank Merge.

With RankMerging, Google tries to understand the value of links of a source based on traffic. And, with the “sampling the internet user traffic to improve search results”, Microsoft tries to group new users with existing user groups so that the search results can be re-ranked for the new user. The same information can be used for the same purpose with different methods and steps. In this context, from two different search engines, we have given two samples that demonstrate how web traffic can affect the re-ranking processes.
- Different Queries, Similar Results, and Selections: This is a patent from Yahoo to find similar, related, and inter-changeable queries based on the users’ behaviors with similar documents. “Matrix Representations of Search Engine Operations to Make Inferences About Documents in a Search Engine Corpus” is a patent of Yahoo that focuses on finding similar queries, if a search engine doesn’t change the results after the query changes, it means that these queries have a close relation. In this context, Google has a little different methodology to extract similar queries. Google can generate “synthetic queries” to perform a search within its own search engine system to retrieve similar documents. If the results include relevant and quality documents from the same context, and topic, it means that the query is actually a “seed query”, and it can have its own centroid within the query cluster group. Different queries with similar results and selections (click behaviors) can signal search engines that these queries are closely related, and the documents will process the same, or closely related information while the queries will be substitutes for each other. Below, you will see an example from Yahoo directly.

And, Yahoo’s methodology and technology behind it for relating queries are a little different. It tries to create “Query Result Matrices” with millions of documents to find overlapping information so that the “NY” and “New York” can be seen as the same.

And, in this context, Entity SEO, or entity-oriented search, and semantic search engines’ value can be understood better. Understanding strings, and measurement of the similarity of strings, and string co-occurring frequencies are two different columns of fact extraction, and information retrieval today. If an SEO is able to think like a search engine, the value of entities will be even more clear. In the context of re-ranking the search results, a search engine can re-rank the documents on the SERP, if a query is clustered with another one, or a document is more relevant to a query from another cluster. The Query Result Matrices from Yahoo, or the Seed Queries and Synthetic queries from Google can affect the re-ranking process.
- Understanding Timely Topics through Alerts and Similar Users with Similar Interest and Their Selections: A search engine can re-rank search results based on timely topics by examining the “alert systems”. Google Alerts can be used to track a competitor, or it can be used to be alerted for a topic when new content is published, or a new event happened. In this context, a search engine can use Alert Systems to understand a user’s interest areas, and also the query terms that are topically relevant. And, via the interest areas, and topics, a search engine can cluster different users based on similar interests to re-rank the search results. The alert terms can be used to cluster the queries. Below, you will see an example from Google within the Patent of “Generation of topical subjects from alert search terms”.

And, a similar patent from Google for the same topic is “Scalable User Clustering Based on Set Similarity”, and a section from it is below.

And, it is clear that focusing on singular queries is costlier than focusing on an entire topic. If a search engine improves search results for a topic, it will benefit users far better than a single query, or a query group based on string similarities.

A section for the re-ranking by clustering similar users based on interest areas and search behaviors from the “Methods and System for Providing a response to a query” (IAC Search & Media) is below.

Another similar patent and approach from Microsoft is “Augmenting user, query, and document triplets using singular value decomposition”. Microsoft sees the query, user, and document as a triplet, and it tries to find the granularity and patterns. In this example, Microsoft tries to cluster the documents, users, and queries at the same time by putting them into a matrix and smoothing the differences or revising the document similarity policy.

In the context of re-ranking, different results with similar queries, similar users with different queries, or different documents with similar queries and more can be used to divide the web and organize the information on the open web by clustering users, queries, and documents to improve the search results quality.
- Paid and Organic Results on the Same Page: The patent of “Systems and methods for removing duplicate search engine results” talks about re-ranking based on the design of the SERP. In other words, a document can be re-ranked if it also appears in the ads. It is interesting to see that the search engine Microsoft Bing didn’t think about removing the ads if the source appears in the organic search results. And, based on the paid and organic search results overlapping, a search engine might think to re-rank the resulting documents by filtering some ads or some of the organic search results. In this context, a search engine can use an algorithm output as a signal for another algorithm as an input. If a source appears as ads and also as an organic search result for a query, the search engine might change the perception of the source with the assumption that the source focuses on a different industry, or they want to cover a broad topic. In this context, a search engine might check the ads of sources to see their overall focus or topics. As a search engine clusters users based on interest, ads can be a signal for clustering sources based on markets too. And, if a source starts to show its organic performance that improves, the search engine can use the previous identity of the brand to start its evaluation in the context of initial ranking and re-ranking.

- High Confidence Spelling Corrections: A search engine re-ranks the search results based on spelling corrections or spelling variations. A word can be spelled differently based on a region, or a cultural group. Thus, a search engine can relate different documents with stronger trust or confidence for ranking if it believes that the correct version or variations of the word’s spelling exist within the web pages. Google announced that they can understand misspelled words, and they can show the correct answers for them within the “Trillions of Questions, No Easy Answers” movie. And, Google also shows the corrected version of a word within the search bar by revision of the query.
Above, a simple query revision from the real-life search experience can be seen. And, below, from the patent of “Query Revision using known highly-ranked queries”. Highly-ranked queries are not just about spelling correcting, it is also about query popularity and the relevance of the query to other clustering groups.

Above it can be seen that the search engine suggests different SERP instances based on “sheets”, such as “linens”, “bedding”, or “bedsheets”. And, the results change at the same time. We can tell that this re-ranking process is similar to the “Advanced Search Users” sample of Yahoo. Because, the patent says that search engine users won’t be able to use advanced search features, or they do not understand the query breadth, specificity, or how things are related to each other. Thus, “query revision” is a must for re-ranking to satisfy the users.

In this context, to group queries, or to re-write the queries, for the same purposes, a different method has been used. Instead of taking only a certain group of users into account, a search engine can use query revision based on the query ranking among other queries to suggest revisions as well as corrections.
- Language Match Between Query and Pages Returned: Language detection is one of the keys to re-ranking. Language detection is used to match the language of the user, the language of the query, and the language of the document. The language of the query might not match the document’s language, but still, the document can be ranked. Thanks to query expansion, and cross-lingual information retrieval, Google can translate a document to show to the searcher. In the same context, English queries are usually used universally. So, language inconsistencies between the documents and the queries shouldn’t be seen as a rule-based system. But still, if the language of the query and the document are not matched, it can signal that the search behavior can’t be satisfied by selecting a foreign language document. In this context, Google can use query-dependent and query-independent ranking factors for language matching. As in neural matching, a search engine can check language matching as well.

And, some sources can be multilingual, or a document can be multilingual. Thus, using different probabilities for language matching is important during the re-ranking process. In Multilingual SEO, using a consistent language for a source, or a section of a source, is significant. With the same possibility, Google also talks about using a “query language” and “document language” ranking for matching the highest possibility.

Above, you can see a relevant section from the patent of the “Ranking search results using language types” patent.
- Labels of Custom Search Results: A search engine can re-rank search results based on the data that has been gathered from the custom search engines. A customs search engine can focus on a specific topic with labels. And, in the patent “Automatically modifying a custom search engine for a website based on administrator input to search results of a specific search query”, Google talks about labels for custom search engines, and how to configure a custom search engine for a website based on its topic and content.

Below, there is a custom search engine example for a specific website.

In the research paper, Structured Data Meets the Web: A Few Observations, Google talks about how the annotations that are generated from custom search engines can be used, and how web pages from search results can have facets.

And, these labels can be “publications” for a library section of a university, or they can be “stuff” for the academic personnel that has been demonstrated within the website. Since the document focuses on the structured data, it also talks about Google Base, Annotation Schemes such as “isAbout”, “locatedIn” and integration of structured data into the unstructured data. In the context of re-ranking, a search engine can use labels and annotations to re-evaluate a webpage or a website section, so that the web page can be re-ranked for more relevant queries in a better way.
- Agent Rank: Agent Rank is an old term from Google Patents. Later, it has been called as “Author Rank”, and later it has been perceived as a part of E-A-T (Expertise-Authoritativeness-Trustworthiness). An author has expertise in a topic, and it can affect the rankings. Especially, in the News SEO area, the journalists’ identity can be seen as a reputation and trust signal. In the “Importance of Prestige and Popularity for a News Source Rank in Google Algorithm” article, I also processed this. Google also started to recognize all the authors from the open web, and it has started to show the articles of the authors within their knowledge panel. And, apparently, Google also can recognize the Authors’ language, or their writing style to compare their articles to the later articles to see their identity. But, still, the term Agent Rank from the patent of “Agent Rank” has a little older and different nature.

In some possible practices for re-ranking, Google talks about website segmentation based on different approaches. A website can be segmented based on author differences, category differences, page type differences, subdomains, or design and layout differences. Agent rank shows that an author can be used to segment a website. Within a web page, a document can signal the identity of the author, and the author can be matched with other authors based on documents, topics, mentions, and linked data.

The Agent Rank patent also mentions the query-dependent and query-independent ranking methods. And, like PageRank, Agent Rank is mentioned as a query-independent ranking factor. Since most of the query-dependent factors focus on relevance, query-independent factors usually focus on the trust signals, along with the quality signals.

In the example above, a search engine matches documents from different websites based on the Agent which is the Author, the creator of the document, or the main content of the document.

The Agent Rank patent also mentions that the overall score can be calculated via “quantity” and “quality” utilization. It also mentions that it is hard to understand which agent has created the document.

Thus, Agent Rank talks about a possible digital signature.

And, Google thinks that people will use these digital signatures to prove that the specific content belongs to them.

Today, thanks to the Natural Language Generation, and Optimization, lots of content has been created without real authorship. In this context, it can be seen that the search engine tries to find different possible solutions for understanding the content creator’s identity, expertise, and relevance to a topic. In this context, they also tried to use Google Plus with authorship. They thought that showing the name of the author within the SERP with an image and Google Plus profile would help to promote the social search engine profile, and also it would be useful for competing against Facebook while solving the content ownership problem. Today, there are structured data, social media platforms that are linked, sentence structure patterns, neural network algorithms to classify an author’s writing style, and trust threshold along with the popularity, and prominence threshold to see who is the real author.
Thus, re-ranking can work with the author’s rank or expertise with the author. A search engine can care more about the author of the document than the publisher’s website. An author can provide trust and real quality for the document. Agent rank was one of the first signals for author rank or the quality perception of authors in order to re-rank search engine result pages. In the context of AI text generation, the authorship, and its importance will continue to grow, and after a point, it will prove it’s a true ranking effect in the world of probabilistic search engines.
What is the Relationship between Initial Ranking and Topical Authority?
The relation between Topical Authority and Initial-ranking is that as the topical authority increases, the initial ranking of a web page increases. Topical Authority is when a web entity becomes authoritative on a topic, its prominence is increased by the search engine, and it has more places in the link distribution, with a higher average ranking. Initial ranking is the first ranking of a web page document on the web search engine’s index for a query. If the web page document belongs to an authoritative source, the initial rank value of the web page will be higher than the non-authoritative sources. Thus, initial-ranking scores can be used to determine the topical authority of the source. An example of the relationship between initial ranking and topical authority can be found below.
- A source can initially be ranked as the 5th for a query that is related to “sociology”.
- The same source can initially be ranked as the 15th for a query that is related to “history”.
- The same source can not be shown for the same query that is related to “history” after 5 minutes.
- The same source can have a continuous ranking after being initially ranked for the query that is related to the “sociology”.
“Continuity of Ranking” is another term that signals the topical authority of the source in the context of initial ranking. A document from a source (website) can be ranked high initially, and it can be de-indexed suddenly. There are two possible reasons for “Discontinued Rankings”, one is that the document has a “continuous ranking” but it is not shown on the SERP due to the data center inconsistencies. A second possible reason is that the search engine is not sure about the relevance of the document to the related query, and it doesn’t trust the source, thus the document is indexed, and de-indexed within a loop until the confidence score is high enough.
In this context, both of the reasons for “Discontinued Rankings” are related to the topical authority. If a source is quality enough, and topically authoritative, it will be served from the Tier 1 servers of Google Search Engine to the users within SERP. A Tier 1 server is the best server of Google to satisfy the search activity of users. In this context, a source from Tier 1 will be indexed faster, and data center inconsistencies will be less likely. The second reason which is the “low confidence score for the quality and relevance of the document” will not be an issue because the source will have historical data for the specific topic along with high authority.
The “continuity of ranking”, and the high “initial-ranking” value will demonstrate the prominence of the source along with its categorical quality.
What is the Relationship between Initial-Ranking and Topical Coverage?
The relationship between initial ranking and topical coverage is that if the topic is covered better by a source, it will have a better initial ranking. If a source comprehensively covers a topic
Topical Coverage is the definition of how well a source covers a topic well. The informational value of a source for the different sections of a topic will represent its topical coverage. Query Templates, Document Templates, Indexability, and Indexing Cost of the source will affect the topical coverage of the source. In this context, the initial ranking will be influenced based on the query type, document type, and template, along with their relation to each other.
To explain the relationship between initial ranking and topical coverage, you can check the example below.
- A source can initially be ranked for the topic of “family financial management” between the 1st and the 5th ranks.
- If the query is from a template such as “What is the definition of X for family financial management”, and if the X is related to other terms from the same topic, a search engine can improve the initial ranking of a document from a source.
- If the query is not from a template, and it is not related to “family financial management”, the search engine can prefer using a lower initial ranking.
- If the source covers related topics by improving its topical coverage, the “non-related query” can have a better contextual relevance for the source, and the initial ranking value can be increased.
A context can be chosen based on the central entity within a cluster of topics, or main entity within only one document, or attribute of the entity that is being processed, or the question and answer format, along with the web page layout. A context can make topical coverage bigger or smaller. A source can cover a topic comprehensively based on a context, but another context can improve its topical coverage’s value. An e-commerce site can cover books generally, and comprehensively, but it might not cover the content of the books, reviews of books, authors of those books, or their background information. Thus, topical coverage can not be evaluated without context determination.
Query Templates and Document Templates for Ranking Algorithms
In the context of relationships of the initial ranking to the topical authority, and topical coverage, the “document template”, “query template”, “search intent template”, “Google datacenters”, “continuity of indexing”, and “continuity of ranking”, “discontinuity of ranking”, “context of topical coverage” have been mentioned. To understand these terms, you can read the “Indexing SEO Case Study” that explains these concepts.
What is Semantic Network?
A Semantic Network involves relational connections with connected concepts. A Semantic Network contains information, definitions, attributes, and historical information for things. A semantic content network design and a semantic network are different things, but they are connected to each other. A semantic network represents the connected meanings with a context or multiple contexts. Relational data types and relational facts between things create the semantic network. Semantic networks and the information graphs and the graph theory itself are related in terms of defining a thing’s prominence, function, benefit, origin, stages, sub and superior types, and parts.
What is a Semantic Content Network?
A Semantic SEO Content Network is a structured content network that describes interconnected concepts, their properties, and relationships, with the possibility of optimal contextual vector, hierarchy, and accurate fact extraction. The Semantic Content Network operates based on the concepts of topical coverage, contextual coverage, and historical data. Topical Coverage is well-known thanks to Topical Authority SEO Case Study, but Topical Coverage can explain the connection between a knowledge domain and the contextual domain along with the contextual layers.
- A contextual domain includes a context qualifier within a knowledge domain.
- A knowledge domain includes an entity and an interesting area around it with possible real-world activity.
- A real-world activity can be connected to search activity.
- An interesting area can have multiple entities with connections.
- A knowledge domain can have multiple contextual domains.
- A context qualifier and a knowledge domain create a contextual domain.
- A contextual domain can include multiple contextual layers.
- A contextual layer includes the same qualifier and the same knowledge domain with a sub-qualifier with a little meaning narrowing while improving the precision and specificity.
- A contextual domain, knowledge domain, context qualifier, subtype context qualifier, contextual layer, interest area, entity, search activity, and real-world activity can be interconnected within different Semantic Content Networks.
- A Semantic Content Network can contribute to a Search Engine’s expansion of its knowledge base by establishing a knowledge-based trust. Knowledge-based Trust is when a source provides high consistency, uniqueness, and usefulness in a topic. Knowledge-base is a Semantic Network and many entities are related to each other from the same topic. Knowledge-base can also be created with the information hosted by a website with the help of a Semantic Content Network.
- A Semantic Network may contain Lexical Semantics, Structural components, Semantic components, and Procedural parts. Lexical Semantics and Structural Components are necessary to express the relationship between the elements that are connected to each other. The semantic Component, on the other hand, contains the definitions and properties of the elements that are connected to each other.
In this context, a Semantic Network can have a presence in many different topics such as diseases, foods, countries, generals, kings, or companies and CEOs. A Semantic Network can be used to develop various types of NLP Algorithms. NLP Algorithms can also implement a Semantic Network with Triple that can be used in Fact Extraction.
How does a Search Engine create a Knowledge-base?
A search engine can create a Knowledge-Base by embedding data collected from any data source into a Semantic Network. A Knowledge-base is the meaning of the information hosted in the Semantic Network. To create a Knowledge-base via Semantic Network, a search engine needs Information Retrieval, Information Extraction, and Fact Extraction processes. Information Retrieval is beneficial for finding the relevance of different phrases to each other. For an ad-hoc retrieval activity, the Information Retrieval relies on query-document matching. Matching a query to a document requires document and query clustering. Query and document clusters have similar features to each other. A search engine can group the entities, facts, attributes, questions, question formats and answers, and answer formats from the documents to each other based on their similarity. A similarity hash can be used to find duplicate documents to create a richer knowledge base by eliminating the exact and near-duplicate documents. A search engine can create a knowledge base via document-query clustering and document-query matching while finding the relevant things to each other. The relevant things to each other will have taxonomic and ontologic connections to each other. These connections will help for generating a Knowledge Base with Triples and Facts. Information Extraction and Information Retrieval are connected to each other in terms of fact extraction. To extract a fact, and turn information that is retrieved into a fact, a search engine will need triples.
What is a Triple?
A triple represents one object and two subjects. Even if the object changes its place with one of the subjects, the connections between the triple elements won’t change. For instance, the proposition “X is the member of Y which is found in Z”, and the proposition “On Z, Y is founded which has the member of X” have the same connections between different entities. Unknown entities, minor entities, named entities, main entities, and central entities are different levels of prominence of an entity within a knowledge domain. A Knowledge Base and a triple are connected to each other. A Knowledge Base can include triples with different relations, and topical aspects. To find accurate information, and turn Extracted Information into Facts, a search engine will need popular consistency over time from authoritative sources for a specific proposition.
What is the difference between a Knowledge Base and a Knowledge Graph?
The only difference between a knowledge base and a knowledge graph is that the knowledge graph has a visual representation of the entities within the knowledge base. Every knowledge base is not a knowledge graph, but every knowledge graph is also a knowledge base. A knowledge base creation is helpful to find the context of the document, its purpose, query-document matching, and understanding of the trustworthiness of a document. A knowledge graph is beneficial for visualization of the knowledge base and making a query within the knowledge graph for a quick representation of the fact.
What is the difference between a Database and a Knowledge Base?
The difference between a database and a knowledge base is that a database has a basic fact without any detail, while a knowledge base has a broader explanation of that fact for possible questions and further related activity to the question. A knowledge base is convenient for organizing information on the internet, while a database is convenient for internal usage with ACID (atomicity, consistency, integrity, durability) properties. A search engine can create a “Browsable Fact Repository” for understanding the search experience of the users. In the past, Google has launched Google Square for finding facts about specific entities. Today, Google Square is not live anymore. But, the Knowledge Base of Google has trillions of answers that are gathered from the web.
What is Contextual Coverage?
Contextual Coverage is the coverage percentage of a context within a content. Contextual coverage involves the context variety and perspective richness of a document with proper sentence structures and conceptual connections. Contextual Coverage, Knowledge Domain, and Contextual Domain are different but connected things to each other. An entity can be a part of a Knowledge Domain, or it can be the whole of a Knowledge Domain. If the entity has a contextual angle for being processed, it will represent a Contextual Domain. If the document has more contexts and angles with different hierarchy levels, it means that it has better contextual coverage. If the contextual domain has many sub-parts, they should be handled as contextual layers. Contextual Domains, Layers, Knowledge Domains, and Contextual Coverage should be processed together to create a Semantic Content Network.

Why does Google extract more Contextual Domains?
Google search engine extracts more and more contextual domains every year because web search engine users search for longer queries. In 2021, at least, more than 40% of the queries were 2 words or more, and %30 of the queries were 3 and more words. Google extracts those contextual domains for serving the information for different variables and conditional differences. Using adverbials, prepositions, or any other kind of query refinement option is beneficial for users to see further information. Google search engine lets users use voice search, and especially the new searching methods including voice search or visual search incite users to use longer queries. Longer queries mean more specificity for more specific situations. All those connected contextual domains help a search engine to satisfy the users with further possible information needs.
An Example of Contextual Domain, Knowledge Domain, and Contextual Layer
Examples of the contextual domain, layer, and knowledge domain represent the demonstration of the differences between them. Below, contextual domain, layer, and knowledge domain differences can be found.
- “What are the advantages of innovation?” is the main question. Its Knowledge Domain is the “Innovation”.
- “What are the advantages of innovation for the automobile industry?” is the Contextual Domain representative. Its main Contextual Domain unites the innovation, automobile industry, and advantages from this connection.
- What are the advantages of innovation for the construction industry? is another Contextual Domain representative. It unites the Construction Industry and Innovation for advantages.
The questions above might have similar connections, but the “Innovation for X Industry” and “Innovation for Y” industries are not the same Contextual Domains. Even if the industries are the same if the “advantages” are changed to “disadvantages” the Contextual Domain won’t be the same again. And, the Knowledge Domain for those questions is “Innovation Advantages”. The questions, below, have further Contextual Domain specificity.
- “What are the advantages of innovation for the electric automobile industry?”
- “What are the advantages of innovation for the factory construction industry?”
Those questions involve the “factory construction industry” and the “electric automobile industry”, in other words, a deeper contextual domain has been chosen. The questions below, have further context qualifiers, and their contextual layers are not the same.
- “What are the advantages of innovation for the electric automobile industry in the UK?”
- “What are the advantages of innovation for the factory construction industry in the USA?”
The “in the UK” and the “in the USA” context qualifiers represent deeper contextual layers. But, all those questions are connected to each other in the same Semantic Network, since they share the same conceptual connections with similar or the same interest areas. Thus, understanding a semantic network is necessary to create a better one with more information and clarity. Understanding context qualifiers are necessary to see the connection between the contextual layers and the contextual domains.
What are the Context Qualifiers?
A context qualifier divides a contextual domain further. A contextual qualifier can be an adverbial, or pronoun that makes the sentence more specific. A context qualifier is a proposition or question refinement. A Contextual Domain can have multiple, deep context layers via the context qualifiers. Context Qualifier and Contextual Layer examples can be found below.
- “What are the energy-saving innovation advantages for the electric automobile industry in the eastern part of the USA?”
- “What are the production innovation advantages for the construction industry in the southern part of the UK?”
The questions above have further deepness with different specifications such as “energy-saving”, or “production”. These questions also have “eastern”, or “southern” type of qualifiers for the geographic citations. Any kind of contextual domain refinement with an extra specificity is a context qualifier. If the context qualifier creates a too-deep contextual area, it is a connected layer of the same contextual domain.
What is the Source Context?
Source Context is the purpose of the source with its identity. A source context affects the position of the brand and its definition. Two different source contexts can’t process the same topic as the same. Different sources with different contexts have to process the topics differently. Source Context and Contextual Domain are connected to each other. “Innovation for Automobile Industry” will be processed based on the source context. If the source is an automobile producer, the “Innovation” will be different, or if it is an AI company, the contextual domain will be processed differently. Based on that, a Semantic Network Creation should be handled with the Source Context. If the Source has a contextual connection with all the things in the Knowledge Domain, and Contextual Domains, properly, the Semantic Content Network will have a better chance.
What is Historical Data for SEO?
Historical Data is the second important component for Topical Authority, after Topical Coverage. Historical data can be accumulated with search engine users’ behaviors and their search activity on the SERP. A search engine can gather implicit user feedback from the search engine users based on context, date, and patterns to evaluate the quality and necessity of a document on the SERP. In the context of initial ranking and re-ranking, historical data can affect a search engine’s decision for continuity of the ranking, and average initial and re-ranking processes.
To make the historical data and the re-ranking, and the initial ranking relation clear, the examples below can be used.
- A website with an average rank of 5.5 for a topic can get a better initial-ranking value on the same topic as its historical data accumulates.
- A website with an average rank of 5.5 for an entity can increase its historical data faster with the content it has for other entities of the same type and can achieve a better initial-ranking value for all entities of the same type.
- A website with an average rank of 5.5 for a query template and query format can delay the re-ranking process after the initial ranking, and improve the initial ranking values.
- Historical data is directly proportional to the topical coverage of the relevant website. Having more impressions and SERP Activity values from the same subject will enable the same source to have more historical data. Therefore, sources that cover the same concepts, interests, and question forms better increase re-ranking and initial ranking.
- If a source covers a topic in more than one language, its historical data will increase faster. Therefore, Multilingual SEO and Multiregional SEO are essential for increasing historical data.
- If a source does not have sufficient content or sufficient quality, even if it does not lose its historical data, historical data may become a signal of poor quality and non-expertise.
- For this reason, it should not be assumed that historical data will always make a website more authoritative.
Why is Historical Data Important for a Search Engine?
Historical Data is the most important data for a search engine. With historical data, a search engine can understand what users are searching for, why they are searching, how many ways they are searching, when they are searching, who are searching, with which device they are searching, in what mood they are searching, and for how long they are searching. A search engine’s algorithm is fed with historical data, developed, and improves SERP quality with announced or unannounced updates. Some example use cases of historical data for a search engine are below.
- If a web page is explored for the first time, Google can understand whether the web page is authoritative or not by checking its first-time linked date.
- A source can have extensive amounts of historical data from seasonal events of the same type, such as concerts of pop-rock groups in Toronto, and Google can try to show events from this specific website for specific types of events.
- A search engine can use historical data to see the brand penetration for different regions.
- A search engine can use historical data to compare different sources for a specific knowledge domain in terms of the search demand of the specific brand.
- If a source is related to certain types of queries for a long time, the source’s context can be seen with a better confidence score.
- If an author, expert, or journalist focuses on a certain topic for a long time, and if there is “consistent scattered information on the web”, a search engine can assign a better relevance to the specific entity for the specific topic.
- A search engine can use historical data to see which query is related to which query.
- A search engine can use historical data to see decay between correlated queries, for instance, if someone searches for a “new car” query, how many days after they search for a “car brand” specifically? And, which car model is compared to which car in which region for what purpose?
- A search engine can use historical data to see the topical authority of a source for a specific knowledge domain.
- A search engine can use historical data to see possible query paths for a specific entity.
- A search engine can use historical data for gathering queries and click logs to calculate click satisfaction models.
- A search engine can use historical data for spam detection, such as if a brand has unusual link velocity despite it doesn’t have any brand name search demand or query, it might be a signal.
- A search engine can use historical data for trying a new source for a certain type of query.
- A search engine can use historical data to find user behavior patterns across different devices or understand the social media behaviors of people.
- A search engine can use historical data to understand society’s needs, or even understand a pandemic’s starting point, or its symptoms of it.
How a Website Can Turn Historical Data and Authority Deficiency into an Advantage for SEO?
A website without historical data might have the advantage of a “low being tested threshold”. “Testing threshold” is the threshold for historical data that determines when a new source (website) will be tested for featured snippets, people also ask questions, and overall better rankings to see whether the source is able to satisfy the users or not. A search engine with probabilistic ranking and degraded relevance score calculation won’t let a source take all rankings over one day, it will happen after a consistent amount of time with a consistent amount of signals. If a source doesn’t have any historical data, it means that the source doesn’t have any negative feedback from the SERP, or quality algorithms of search engines.
In this context, a new source can create enormous amounts of positive historical data within a short time. And, if a source has a new content network with better accuracy, clarity, and informational value for its content, a search engine can decide to try the new source on the SERP against the existing sources. Fastly growing-historical data for a source can trigger a rapid re-ranking process with the help of better initial rankings.
To use historical data for better SEO performance, the methods and articles below can be followed.
- Having clear internal link circulation that is cleaned from internal redirects, or link rot.
- Having clear indexing signals for all the URLs within the source.
- Having a contextual and less costly crawl path for the search engine crawlers
- Having clearly distinctive but adjunct content pieces with contextual relevance
- Using internal links for creating better relevance
- Making the search engine discover the source with all possible topically relevant content pieces in one day.
- Having completely static HTML pages with light CSS, and nearly no need for rendering JS in terms of the main content.
- Having clearly and naturally written relevant title tags.
- Creating a clear contextual vector and contextual hierarchy for all the content pieces.
- Using semantically related propositions for the specific topic.
How to Use Robots.txt for Initial Ranking in the context of SEO?
Robots.txt can help a new website to rank better initially and to create positive historical data within a short time. To use Robots.txt for better initial ranking, use the steps below in the context of SEO.
- Disallow all the websites from day one.
- Do not let any other search engine crawlers crawl the website.
- Do not create any kind of indexing signal.
- Do not create any kind of external reference (link), or inferred reference (mention) for the source.
- Do not open all of your content to the open web suddenly.
- Be sure that you record all sources and their content in the web archive.
- After implementing the steps for using historical data usage benefits, remove the disallow command within robots.txt
- Wait for Google and other search engines to crawl, explore, and evaluate naturally, and do not intervene in the algorithms’ decision trees with URL Inspection Tool, or any other manual work.
Robots.txt can be a tremendously useful tool for making a website rank faster and better. If Google sees a source first time on the open web, or after a tremendous amount of time, crawlers of Google will crawl all web page URLs that they can find, and they will render the JavaScript while caching the related sources for these URLs such as JS, CSS, Images, and Font Files. In this context, using Robots.txt for creating better historical data and the initial-ranking score has another benefit which is being crawled with all URLs, and being rendered completely for first-time evaluation algorithms.
What is the Initial Evaluation for a Search Engine?
Initial Evaluation can happen for a web page, or for a website in the context of initial ranking. A new source on the web can be initially evaluated with broader aspects by a search engine. A new source can be evaluated to see its main context, knowledge domain, its owners, main topic, site-wide n-grams, corporate information, and overall quality to be classified and clustered with the previously similar sources. If a source is quality enough, a search engine can classify the source with other sources that are most qualified for a specific source. This quality and authority assignment and clustering will happen during the initial evaluation.
If a source tries to change its main topic, knowledge domain, document template, and overall quality along with identity, it will be harder to perform and convince the search engine. Thus, a source without any historical data has the benefit of saying “hello” for the first time to the search engine to introduce its identity, and targets.
To pass the initial evaluation successfully, a new source shouldn’t have any missing content pieces, layout inconvenience, more crawling costs, unclear content pieces, and wrong organized content design. By making itself classified with the most quality sources initially, a website can make a better launch, and a better initial ranking score will create an endless cumulative effect during the journey of origin within historical data.
What is the Importance of Internal Links for Initial Ranking in the context of SEO?
The importance of internal links for initial ranking involves signals for indexing, the value of PageRank, the confidence of search engines for ranking, and the relevance of the web page document for the targeted queries by supporting the source’s factual information organization.
If a search engine finds a quality web document without any internal links, and, if the related URL is not listed within the sitemap, it means that the “initial evaluation of the web page” will include a low confidence score for indexing. An internal link carries meaning for “indexing”, and having an indexing command for a newly published URL will help a search engine to be confident enough for ranking the webpage.
An internal or external link flows PageRank, and if a newly added content has an internal reference, or external reference, and is crowdsourced from social media platforms, it means that the specific web page will have a better initial ranking from the search engine. Supporting newly published content with external and internal PageRank flow, and referral traffic from external sources will help content have a better initial ranking by decreasing the indexing delay.
An internal link from a relevant content piece and an anchor text will improve the initial ranking of a new web page document since it will improve the relevance of the specific content piece by signaling the purpose of the web page.
In the context of re-ranking, and initial ranking processes of search engine optimization, internal links, external links, mentions, and references without a link, social-proof and social media activity for URLs’ effects can be found below.
- An internal link increases the confidence score for indexing.
- An internal link increases the frequency of search engine hits for a specific web page.
- An internal link increases the relevance of the web page to the source, and to the specific topic.
- An internal link passes PageRank to the specific web page to help for better initial ranking directly.
- An internal link with relevant anchor text helps a new web page to be relevant for a specific query, phrase, or search behavior with better proximity.
- An internal link without logic can be eliminated by the Cautious Surfer and Reasonable Surfer.
- An internal link without prominence can signal that the web page is not prominent.
- An internal link with repetitive patterns might be ignored by the search engine for ranking purposes, unlike crawling purposes.
- There is no specific, and optimum internal link count for a specific content piece.
- An internal link can signal a web page’s topic with semantic relevance, and seed query clusters.
- An internal link text and title of the web page can help a web page to improve its contextual sharpness.
- An internal link text should be used only for a specific web page for ranking purposes, whether it is initial, or re-ranking.
- A conflicting internal link text for the link target can cause discontinuity of indexing, along with demotion of the source.
- An internal link from non-accurate content can harm the organic search performance of other content in terms of initial-ranking and re-ranking.
- Annotation text can signal the consistency of the contextual connection between two different web pages via an internal link.
- Annotation text can be texted around the link text or text around the phrase of the link text.
- A search engine can check all the link texts from competing web pages to see how topics, verbs, adjectives, and nouns are connected to each other.
- A search engine can use the historical data of the link source to improve confidence in the new web page for a better initial ranking.
- The queries of the link source can affect the performance of the link target’s web page for the related queries.
- Re-ranking process of the link source can impact the re-ranking and initial ranking of the link target web page.
- The anchor text-link text should target the seed query of the targeted web page, and the specific seed query should exist in the targeted web page’s content with different question-answer pairs.
- Social media activity, crowdsourcing, and social-proofing can impact search engines’ confidence for indexing with a better initial ranking of a document with enough level of feedback from the open web within consistency.
- Inferred links, mentions, and descriptions of a named entity, or its services, products, and sub-brands can help a search engine to improve the relevance of the source, and these types of links without hypertext can influence the initial ranking and re-ranking.
- A search engine can differentiate the block links, isolated links, single page links, or boilerplate links from each other by using them on different levels in order to re-rank documents or adjust initial ranking.
- The total count of links, the proximity of links, the relevance of anchor texts, linked web pages, possible search activities, their layout, and web page purposes can affect the re-ranking and initial ranking.
- A search engine can ignore if the web page includes an excessive amount of internal links, and sometimes these links can be used for exploring, or creating a shorter crawler exploration path. An excessive amount of internal links can modify the re-ranking and initial ranking.
- A search engine can delay the effect of an internal link based on its consistency for initial ranking, or re-ranking.
- A search engine can ignore the effect of an internal link, or reverse its effect for ranking purposes, if the link’s position, context, and existence are not consistent.
How many internal links should be used for improving the initial ranking in Google SERP?
To improve the initial ranking on the Google SERP via internal links, there is no specific number or quantity for the need. A new web page should be linked to the contextually relevant web pages by explaining the relevance of the two specific web pages. Based on the topic, if there are possible 5, or 10 connections between two web pages, these connections should be explained.
When it comes to internal links, SEO should focus on the quality, and necessity of the internal links, instead of their time. The annotation text, anchor text, and the location, style, and font size of the specific link, or position of the image link will be more prominent than its quantity value.
If a source doesn’t use its internal links with logic, based on the Cautious Surfer, and Intelligent-Reasonable Surfer models of search engines, a search engine can ignore the internal links. An algorithm can decide that the specific links are helpful for understanding the value, and relevance of the specific web page for a query, and search intent, but another algorithm can decide that the specific links are pointless. And, in the algorithmic hierarchy, the second decision can harm the re-ranking process.
Thus, sometimes SEOs experience that a newly indexed web page disappears from the SERP, or it changes its rankings based on specifically chosen spots repeatedly. This process is the evaluation of the first decisions of the search engine, based on the other competitor’s web pages. The first decisions of the search engine algorithms can be evaluated by the re-ranking algorithms, and based on the consistency, accuracy, and quality of the source the re-ranking follows the initial ranking.
Similar ranking differences and velocity can happen due to the data center differences of Google, or other search engines, but a data center difference caused ranking velocity can be audited by checking the remote address of the response, and data-center related ranking differences do not last, or consistent as the re-ranking process caused differences.
How does an Internal Link signal the Semantic Relevance of a Web Page to a Topic?
Internal Links can signal the semantic relevance of a web page to a topic based on Semantic Annotations. An internal link and its text (link text) can be a part of WordNet, along with a query cluster of the search engine. A search engine can use anchor texts of different web pages to understand which topic is connected to which another topic. If these phrases from anchor texts are used within a sequential search activity or correlated search activity, they can be clustered together. If these anchor texts are lemmatized versions of the verbs from the same WordNet, or they are the types, parts, and features of a specific named entity, a search engine can cluster the targeted web pages for a specific seed query group.
To increase the confidence of search engines for the reliability of the anchor texts, a contextual vector should stay on the same topic, and related co-occurring phrases matrix from start to end, so that an anchor text can have the feature of a semantic label.
In the context of Initial Ranking, using a semantically relevant anchor text-link text will help a source to rank its content better initially, and it will improve the continuity of the indexing for the web page by helping the re-ranking process.
Note: Using the same anchor text across all websites can signal a search engine that the internal links are not natural, and do not have a logical relevance. Thus, phrase variations, synonymization, and lemmatization should be used for internal links.
How can annotation text affect the Initial-ranking?
Annotation text can be text on the left side and on the right side of the link text, or surrounding text, the next paragraph, or the previous paragraph. Phrases from the link text can be used for uniting the annotation text. Annotation text can signal the link’s purpose and logic. If annotation text includes a negative sentiment, the link can be used as a “negative reference”, if the annotation text can include too positive sensitivity, it can be perceived as “marketing”. In this context, a link’s efficiency can be delayed. If newly published content loses its internal links that exist during the initial evaluation of the search engine, or the anchor texts change, and links’ positions change, a search engine can change the initial ranking value that has been assigned previously. If these types of inconsistencies continue all the time, a search engine can ignore some internal links, anchor texts, and their PageRank, or relevance.
What is the Importance of Website Segmentation for Initial Ranking in the Context of SEO?
The importance of website segmentation for the ranking process is related to the similarity of grouped content, and search engines’ clustering fundamentals. Every search engine relies on clustering; they can cluster users, contexts, topics, queries, documents, IP Addresses, links, anchor texts, layouts, templates, language tonality, regions, or any other kind of entity. In this context, if a source clusters its similar content together based on its relevance to each other, it can help search engines to crawl, understand, evaluate, index, and rank a web page.
How can a search engine segment a website?
A search engine creates different types of segments for a website based on the following criteria.
- Authors of articles.
- URL structure.
- Mutual verbs and nouns within the titles.
- Based on web page layout, and purpose.
- Based on topicality.
- Based on breadcrumbs.
- Based on traffic behaviors.
- Based on the queries that web pages rank for.
- Based on different types of schema markup usage.
- Based on the distance from the index, or click depth.
- Based on internally being linked frequency.
- Based on the type of content such as service, product, cooperation, blog post, article, recipe, movie, etc.
- Based on subdomains, or domain extensions.
In a website to strengthen the contextual sharpness, and relevance of a web page to improve its initial ranking, and re-ranking, all signals should align with each other, and search engines shouldn’t have a dilemma for segmenting the website with different methods in different results.
What are the example usage of website segments for initial ranking and re-ranking?
Example use cases of initial ranking and re-ranking with website segments are given below.
- In the News SEO, website locations, or website segments can be used for tracking new content via the content publisher center.
- A search engine can use different website segments to understand the newly published content, and it can decrease the cost of retrieval for evaluation, a strongly connected web page for a segment can have a better initial ranking and re-ranking.
- Nested website segments can signal the relevance of a specific layer to another one with the help of taxonomy within Semantic SEO.
- Interconnected website segments can signal the comprehensiveness of a source in a better way than a distracted source organization with the help of ontology within Semantic SEO.
- A properly-organized site can be crawled faster, and ranked with better confidence, thanks to its contextually divided site tree.
- A search engine can compare the crawl path exploration, or content groups, of different websites to see their effect on the cost of retrieving.
- A search engine can understand the document templates, query templates, and intent templates better based on website segments for ranking, and indexing purposes.
What is the Relation Between the Assigned Initial Ranking Potential of a Source and Semantic SEO?
Assigned Initial Ranking Potential of a source refers to the potential improvement for the initial ranking of a website for a specific topic, group of queries, categorical themes, and entities which are terms from Semantic Relations of things, and phrases. If a website has more impressions from certain types of queries, a categorical quality can be assigned. Or, if a website has topical relevance with its site-wide N-grams and site-wide anchor texts for a topic, a better initial ranking can be triggered when the source improves its semantically created content network for the specific topic.
Semantic SEO’s main relation with initial ranking is that if a source is organized with semantically relevant thematic seed queries, and entities that are associated with these phrases, it will have a better confidence score for ranking higher initially since it proves its prominence. To use the Semantic SEO for better initial-ranking potential value, a source should cover the semantically relevant topics, search intents, attributes of entities, qualifier portions of question formats, and all the relevant n-grams without diluting the ranking signals of web pages by creating a contextual sharpness, and clear contextual relevance.
How to Use Phrase-based Indexing Rules to boost the Initial-ranking Potential of a Website?
Phrase-based Indexing patents of Google have been expanded by Anna Patterson many times. Understanding Anna Patterson’s methodologies and perspectives to cluster the terms on a web page will help an SEO to understand the perspective of a search engine for information retrieval. Google, Microsoft Bing, Yandex, and other search engines can use the phrases to cluster the documents, and also queries. Phrases can be used for matching queries to documents, questions to answers, and entities to entities. Thus, even for entity-oriented search, phrases will continue to protect their prominence for the organization of the open web. In the next sections, usage methods of phrase-based indexing for information retrieval from a search engine’s point of view will be explained. This information will be used for supporting the Semantic SEO efforts for better Initial and Re-ranking processes.
How can a Search Engine use Phrase-based Indexing for Initial Ranking?
- A search engine can filter the top phrases of a website, and it can use “phrasification” for scoring different phrases’ relevance, lastly.
- It can use phrase-based information retrieval to see a website’s relevance for a specific query.
- A search engine can use a phrase posting list to see which words are being hit by the web page document.
- Phrase-based indexing can be costly for search engines if a search engine doesn’t create a proper phrase-list, representative phrases, or phrase clusters, because phrase permutations and phrase combinations can be endless, also phrases are being refreshed repeatedly.
- Co-occurring matrixes of phrases can signal the word of a phrase within a sentence, paragraph, or entire content.
- Discordant phrases or rarely seen phrase co-occurrences can be seen as spam, and also they can be seen as new and unique information.
- To differentiate spam from new and unique information, search engines can use different algorithm combinations such as entity-oriented search algorithms, fact extraction, accuracy checking, or authority of the source with its historical data. Phrase-based indexing understanding can be used for initial ranking.
- Phrases can strengthen the relevance of a document to a certain type of entity, or topic.
- A phrase-based indexing system can create a phrase-based taxonomy. Phrases can have different levels of specificity and broadness. Query breadth can affect the phrase taxonomy, and co-occurrence of different phrases from different taxonomy hierarchies will help a search engine to order information based on specificity level.
- A search engine can assign a PhraseRank based on the good and bad phrases. A good phrase can have a different meaning than the individual sections, and it can be supported by surrounding text. A good phrase can be used with synonyms and related terms, with word proximity. PhraseRank can be increased and decreased based on the document’s information, and relevance level.
- A search engine can use phrase-based indexing for understanding the subsections’ differences in a web page. Phrases above, phrases in the middle, and phrases at the bottom can change based on the co-occurrence matrix.
- A search engine can use phrases to understand a new website’s main topic and information level.
- A search engine can use phrases to predict other phrases within a web page.
- A search engine can create multiple indexes to show a user based on phrases. According to the previous queries, and users’ selection, search engines can switch the supplementary index and primary index to satisfy the users’ possible search intents.
- A search engine can use entities to relate phrases with them. Related phrases with an entity can be attributed to the connections of entities to each other.
- A search engine can use phrases from the link texts, and compare them to the phrases within the titles.
- A search engine can use phrases from the link texts, and matching titles to compare them to the queries, and query result behaviors of users.
- A search engine can gather the first-time searched, and first-time encountered phrases to expand its organized index to satisfy the newly encountered search intents, and behaviors.
- A search engine can use phrases from comments, poems, novels, or different types of information formats to understand a content piece’s genre, purpose, and relation to the topic.
- A search engine can generate new phrases to use them as queries to organize the information on the web by creating indexes for possible queries
- A search engine can cluster the pre-defined indexes under the seed queries, and organize them according to the query templates, mutual queries, and search behavior patterns.
- A search engine can compare the phrases at the left of the current phrase and the phrases from the right side.
- The right-side phrases and left-side phrases will show different characteristics in terms of co-occurrence.
- A search engine can use N-grams, Skip-grams and Word2Vec, GloVe to understand a phrase’s meaning, and relation to others.
- A search engine can assign multiple meanings, and contexts, to a phrase based on the co-occurrence of other proximate phrases that are acquired with different methodologies.
Below, to explain these examples from an old Googler’s perspective, there is an image. The sentences below belong to Matt Cutts.

The example above is similar to the example from Anna Patterson, who is the inventor of the phrase-based indexing patents of Google.
How to Use the Co-occurrence Matrix for Boosting Initial-Ranking Potential of a Source?
To use the Co-occurrence matrix to boost the initial ranking of a new website (potential source), an SEO should use the co-occurring phrases together with word proximity. Strongly related phrases for a word can be determined from the left side and also the right side. A co-occurrence matrix can strongly change according to the left side of a word, and the right side of a word. Thus, search engines use N-grams and Skip-grams to understand the relevance and informational value of a web page to a query. For instance, the word “White House ” can be used frequently for the current president of the USA, but after the specific named entity which is the person that is the president of the USA has retired, this co-occurrence level will be weaker. To use the initial ranking with an SEO Project, site-wide, subfolder-wide, and individual page-wide n-grams, co-occurrences, flow of phrases from the beginning of the content to the end of content, and anchor text phrases should be organized for the targeted queries. Organization of co-occurring phrases can’t be done based on numeric values, or density-related understanding. Phrases should be used with information, facts, and proofs that explain the things that are searched, and provide click satisfaction to the users.
For instance, if a new website is about “Fruits”, phrases that will be distributed among the website pages should have relevance and intelligence to be used together. Titles, introductions, headings, texts after headings, URLs, alternative fruits to a specific fruit, similar fruits to a specific fruit, and recipes that the fruit can be used, all should have a mutual ground. If the specific fruit is “apple” for a web page, the linkable pages, and related information should be determined before by the SEO. The related words for nutrition, and recipes, or the cultural and biological explanations will be different. Thus, creating a clear content design is a tradition for semantic SEO and search engine understanding.
How to Generate Questions for Better Contextual Relevance?
Contextual Relevance is the relevance between two different things based on a mutual situation, feature, or criteria. A contextual relevance can be generated based on connections, and different types of relation types. Two entities can have different relations for a search engine. This relation can be extracted from a propositional sentence as a fact, or it can be inferred from the co-occurring phrases. To generate questions for better contextual relevance, the context’s prominence for the entities should be measured. If the entity is “lamb”, the “types, parts, functions, prices” of lambs will reflect a stronger contextual relevance than the “history” of lamb. Both the lamb and the attributes of the lamb such as history, price, and parts are unnamed entities, and with their connection, they generate different contextual domains. An entity can be an attribute for another entity based on the question. To generate a contextual relevance, both the entity, attribute, and their prominent context should exist within the question. To match the answer with the question, a search engine matches the question and answer format. The popular answer formats or shorter answer formats can be seen as better candidate passage answers than the longer and grammatically harder sentences. In this context, understanding the entities, and natural language processing, along with the methodologies of a search engine to perceive the relevance, facts, and accuracy should be practiced by the content creators to generate better questions for better contextual relevance.
Last Thoughts on Initial-ranking, Re-ranking, and the Holistic SEO
Initial-ranking and Re-ranking are the terms belonging to the search engine creators. Without understanding the minds behind a search engine, and using their concepts to understand the information on the web along with users’ feedback for this information, an advanced SEO Concept can’t be improved. Search Engine Official statements won’t include these types of terms, or these types of information for Search Engine Optimization experts, or content creators on the open web. To create a better understanding of SEO, initial ranking, and re-ranking are two concepts that SEOs should use, and perceive like they are stages of their SEO Projects.
During the SEO Case Study, and the subject websites for this SEO Case Study, I have used the terms “initial-ranking”, and “re-ranking” to explain the things to my clients. When the concepts of the search engine creators are understood, it will be easier to interpret the behaviors of a search engine. Most of the time, SEOs approach SEO-related practices with binary codes such as “it works”, and “it doesn’t work”. In SEO, some practices only work with other parallelly implemented practices, and “re-ranking”, and “initial-ranking” are two concepts that can differentiate the SEO practices for different stages. Initial ranking can be seen as the beginning of a web page’s search lifecycle, while re-ranking can be seen as the “improving cycle” of a web page for the search ecosystem. Any data that will be collected by the search engine will be used for evaluation of the source, subfolder, and web page to rank it for different queries at different times. All these complex motions can be more clear thanks to the Initial-ranking and Re-ranking.

- Sliding Window - August 12, 2024
- B2P Marketing: How it Works, Benefits, and Strategies - April 26, 2024
- SEO for Casino Websites: A SEO Case Study for the Bet and Gamble Industry - February 5, 2024


What a great post, thank you for writing it.
Hi Koray, great post. So you recommend to complete the topical map for a new website in a sufficient manner in order to help Google to understand the website topic and therefore achieve higher initial rank and more success for the re-ranking iterations?
And: Maybe I missed it in the case study, but did you publish all articles for the case study website at once + did you allow indexation through the search engine for these webpages all at once?
It was gradual and ease-in-out publication frequency. Search engines knew the websites when the project started.
And, thanks for the kind words.
Hey Koray, Thanks for the article 🙂 For few sections, I couldn’t get the concept. It would be great help if you can update this post with examples so that I could learn and apply on the website.
Thank You!
Hello Kevin,
Thanks for your kind words. I will be updating it after publishing some videos on my YouTube Channel.
Thanks for reading it.
Merhaba Koray.
Interesting study and very informative. I like how you illustrate everything in detail, and I always watch your videos in full. But what I am looking for is how you handle new sites. Do you publish 5-10 posts right at the beginning (1 post per day) or what scheme do you follow here?
Another question is whether you should really block a website’s feed. In your robots.txt file, you block */feed, but in another article, you recommend adding your website to an RSS feed. Can you explain this in more detail?
Hello Adnan,
Thank you for your comment, it is really valuable to us.
The Googlebot doesn’t index the “feed”, “Google-feedfetcher” does, and it doesn’t listen to the Robots.txt files.
When it comes to the publication frequency for higher Google rankings, try to publish at least 20 articles at once.
Hello Koray,
First of all thank you and grateful for all the efforts you put in each post (feels like book).
I have a doubt you are telling to target single macro context in each post (or page) but for a simple query like “What is Modular kitchen?” the answer might be completed within 2-3 sentences but competitors covering Almost all the topics (definition, types, uses) under that query. So I have a doubt shall I publish that 2-3 sentences as one post or Do I have to follow what others doing?
Also as you said it may dilute the page context but there are competitors doing the exact method and ranking for that multiple keywords. expecting your kind response. Thank you.
Hello Satheesh,
Thank you for your comment, it is valuable to us. Let me try to help you.
The “macro context” represents the main purpose of the specific web page, and it should focus on the “same entity”.
In your example, you are using the concept of a “Modular Kitchen”. If “modular kitchen” is the entity for ranking purposes in the context of organic growth, processing the “definition, types, uses” are the attributes.
In other words, the web page still stays in the same macro context, but the micro contexts change from one attribute to another based on the same specific entity.
This might be problematic if only the specific query has a “different template” than the actual “title”, or there are multiple attributes with really high-search demand, which requires opening multiple new pages dedicated to the attributes for closer relevance.
And, thank you for your comments, they are really valuable for me.
Understood. Once again Thank you koray for the valuable feedback and insight. Waiting for the SEMANTIC SEO COURSE…
Thank you so much, Satheesh!
Hi Koray,
Very informative. Can you please share the related resource for “Query parsing and processing methodologies”.
This is the line from the above article = “To learn more about query parsing and processing methods of a search engine, you can read one of the related presentations. “
Hey Rajkumar,
Happy to see your comment, and friendly thoughts. Here is the mentioned presentation about query parsing and processing in the context of re-ranking: https://www.slideshare.net/KorayGbr/semantic-search-engine-semantic-search-and-query-parsing-with-phrases-and-entities
outstanding koray
Thanks for sharing a helpful post
Thanks for kind comment.